Azure Databricks.
AZURE DATABRICKS
Azure Databricks combines data warehouses and data lakes into a lakehouse architecture. Unify all your data, analytics and AI on one platform.
What is | Architecture | Integrations | Pricing | Features | Support

What is Azure Databricks?
Azure Databricks is a unified analytics platform that enables organizations to build data pipelines, machine learning models, and dashboards at scale. It is a fully managed service that runs on Azure, and it provides a unified workspace for data scientists, data engineers, and business analysts to collaborate on projects.
Azure Databricks is built on top of Apache Spark, a popular open-source distributed computing framework. It provides an optimized Spark environment, as well as a suite of tools and features that make it easier to build and deploy analytics and AI applications.
Azure Databricks is a popular choice for a variety of use cases, including:
- Data engineering: Azure Databricks can be used to build and manage data pipelines that process and transform large datasets.
- Machine learning: Azure Databricks provides a variety of tools and libraries for building and deploying machine learning models.
- Business intelligence: Azure Databricks can be used to create dashboards and reports that provide insights into data.
Azure Databricks is also tightly integrated with other Azure services, such as Azure Storage, Azure SQL Database, and Azure Machine Learning Studio. This makes it easy to build and deploy end-to-end analytics and AI solutions on Azure.
Here are some of the benefits of using Azure Databricks:
- Unified platform: Azure Databricks provides a single platform for data engineering, data science, and business intelligence. This makes it easier for teams to collaborate on projects and share data.
- Scalability: Azure Databricks can scale to meet the needs of the most demanding workloads. It can handle petabytes of data and thousands of concurrent users.
- Performance: Azure Databricks is optimized for performance, and it can deliver insights from data quickly and efficiently.
- Ease of use: Azure Databricks is easy to use, and it provides a variety of tools and features to help users get started quickly.
Overall, Azure Databricks is a powerful and versatile analytics platform that can be used to solve a wide range of problems. It is a good choice for organizations of all sizes that are looking to build and deploy end-to-end analytics and AI solutions.
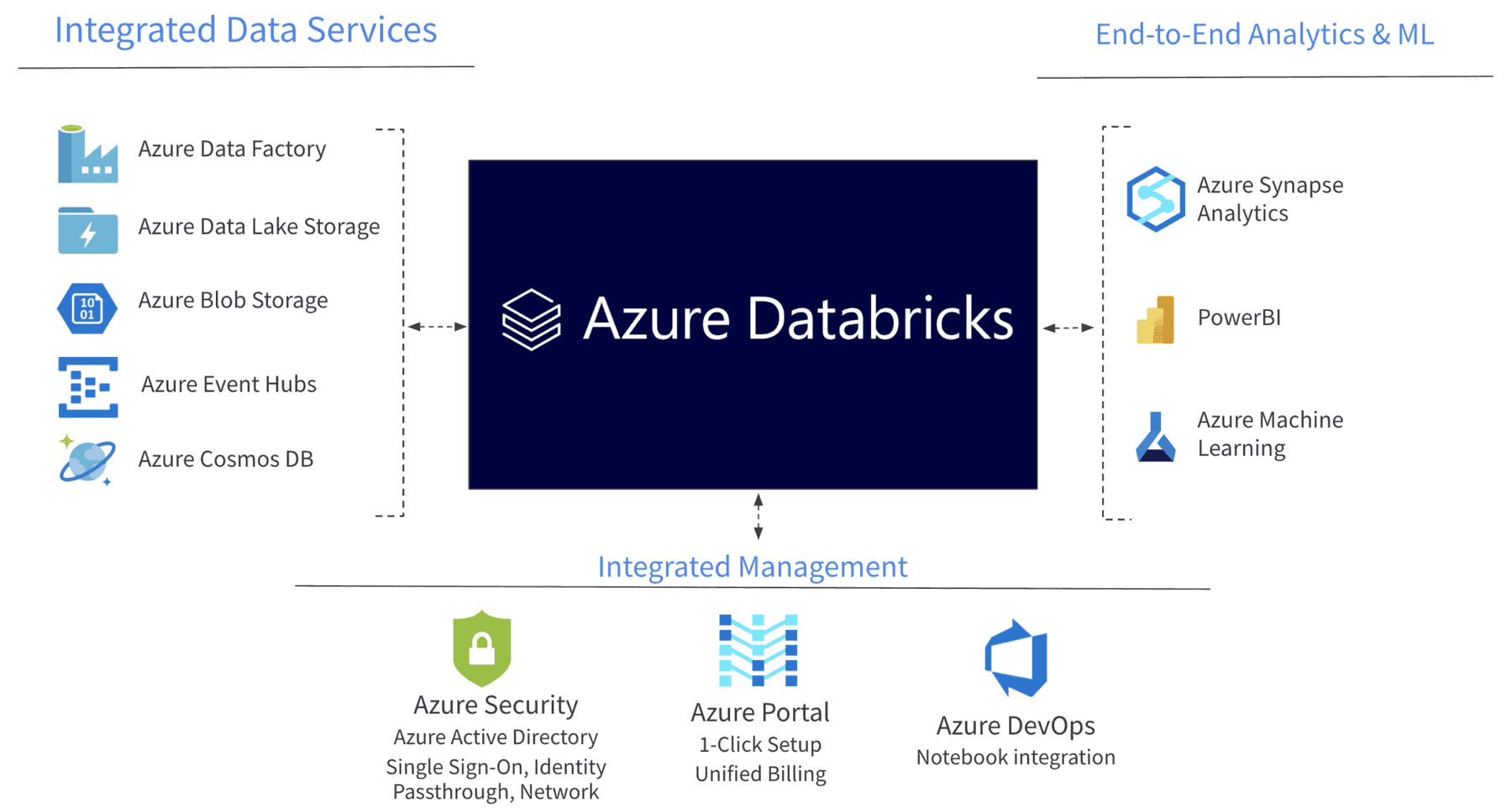
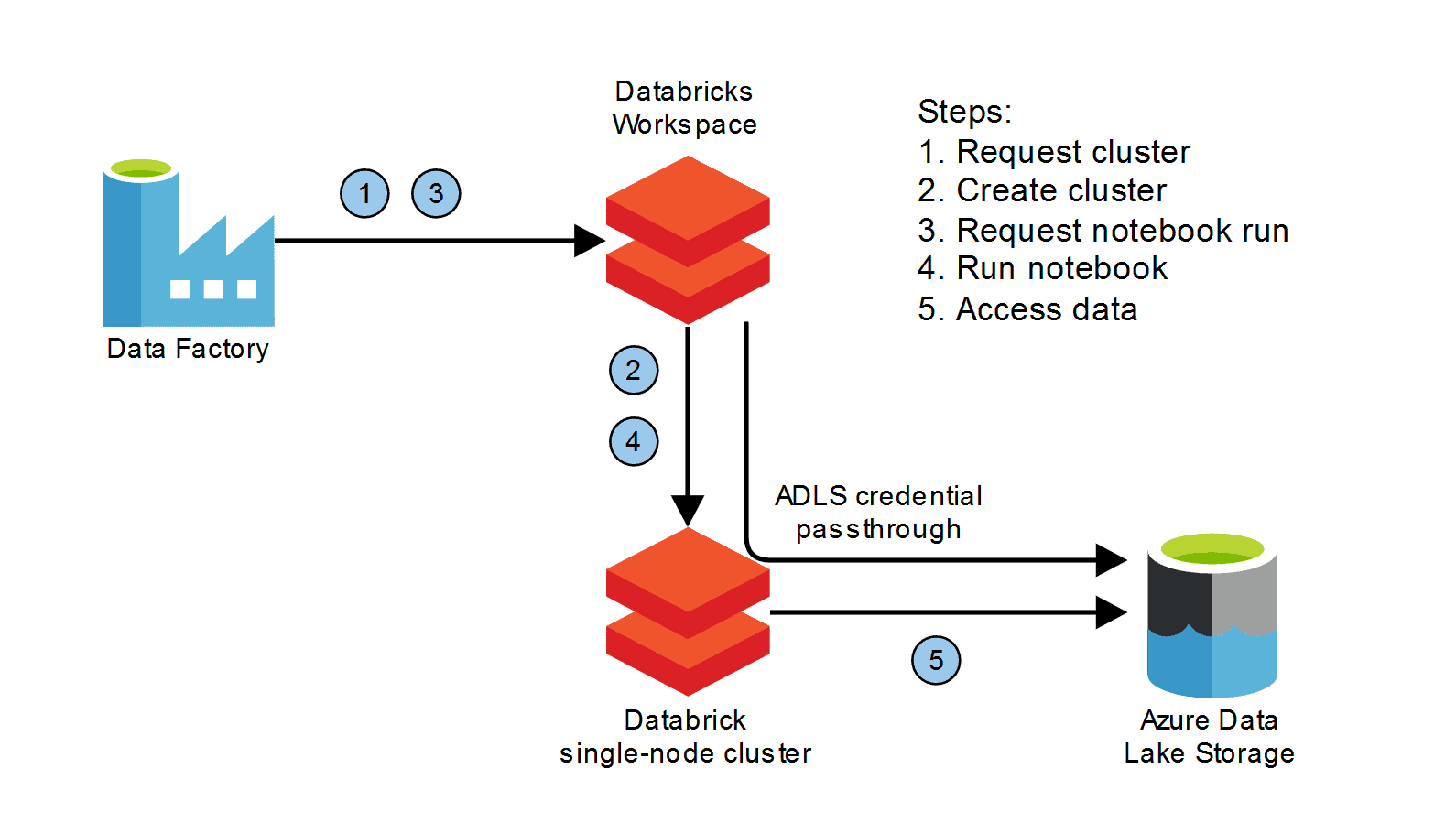
The Best Azure Databricks Architecture
The best Azure Databricks architecture depends on the specific needs of your organization and the use cases you are planning to support. However, there are some general best practices that you can follow to design a scalable, efficient, and secure architecture.
Here are some tips for designing the best Azure Databricks architecture:
- Use a layered architecture: A layered architecture separates your data and workloads into different layers, such as a landing zone, a data lake, and a data warehouse. This makes it easier to manage your data and workloads, and it also improves performance and security.
- Use Delta Lake: Delta Lake is an open-source storage format that provides ACID transactions and other features that make it ideal for storing data in Azure Databricks. It is also compatible with Spark, so you can use existing Spark code to process and transform your data.
- Use autoscaling: Autoscaling allows Azure Databricks to automatically scale your clusters up or down based on the demand. This can help you to save money on compute costs.
- Use managed services: Azure Databricks provides a variety of managed services, such as managed notebooks and managed streaming. These services can help you to reduce the operational overhead of managing your Azure Databricks environment.
- Use security features: Azure Databricks provides a variety of security features, such as role-based access control (RBAC) and encryption. These features can help you to protect your data and workloads from unauthorized access.
Here is an example of a layered Azure Databricks architecture:
- Landing zone: The landing zone is a temporary storage area where data is first ingested into Azure Databricks. The landing zone can be stored in Azure Blob Storage or Azure Data Lake Storage Gen2.
- Data lake: The data lake is a central repository for all of your data, regardless of its format or structure. The data lake can be stored in Azure Data Lake Blob Storage or Azure Data Lake Storage Gen2.
- Data warehouse: The data warehouse is a highly optimized data store for running analytical queries and reports. The Azure data warehouse can be stored in Azure Synapse Analytics or Azure SQL Database. See the differences between a data lake and data warehouse.
The Azure Databricks clusters can access data in the landing zone and the data lake to perform processing and transformation tasks. The processed and transformed data can then be loaded into the data warehouse for analytical purposes.
This is just one example of an Azure Databricks architecture. The specific architecture that you choose will depend on your specific needs and use cases.
Here are some additional best practices for designing an Azure Databricks architecture:
- Use a version control system: Use a version control system, such as Git, to track changes to your Azure Databricks notebooks and other code. This will make it easier to collaborate with others and to roll back changes if necessary.
- Use unit tests: Use unit tests to test your Azure Databricks code. This will help you to identify and fix bugs early on.
- Use integration tests: Use integration tests to test your Azure Databricks code with other components of your architecture, such as your data sources and data warehouse. This will help you to ensure that your entire architecture is working together as expected.
- Monitor your architecture: Monitor your Azure Databricks architecture to identify and resolve any performance or security issues. You can use Azure Databricks Monitoring to monitor your clusters and jobs.
By following these best practices, you can design an Azure Databricks architecture that is scalable, efficient, secure, and reliable.
Databricks Key Azure Integrations
Databricks offers several integrations with Azure to provide a seamless and powerful data analytics and machine learning environment. These integrations leverage the capabilities of Azure services to enhance data engineering, data science, and machine learning workflows.
Here are the major Databricks integrations with Azure:
Azure Databricks service – Azure Databricks itself is a managed Apache Spark and data analytics platform that is tightly integrated with Azure. It provides a collaborative environment for data engineers and data scientists to work together on big data and machine learning projects.
Azure blob storage – Databricks can seamlessly integrate with Azure Blob Storage, making it easy to access and process data stored in Azure Data Lake Storage or Azure Blob Storage containers. This integration allows you to read and write data efficiently, enhancing data engineering workflows.
Azure machine learning – Databricks can integrate with Azure Machine Learning services, allowing data scientists to train and deploy machine learning models using Databricks clusters and then easily deploy them to Azure for production use.
Azure monitor and Azure log analytics – Databricks can integrate with Azure Monitor and Azure Log Analytics to provide monitoring, logging, and diagnostic capabilities for your Databricks workloads. This integration helps in performance tuning and troubleshooting.
Azure active directory – Single Sign-On with Azure Active Directory is the best way to sign in to Azure Databricks. Azure Databricks also supports automated user provisioning with Azure AD to create new users, give them the proper level of access, and remove users to deprovision access.
Azure data lake storage – The Azure Databricks native connector to ADLS supports multiple methods of access to your data lake. Simplify data access security by using the same Azure AD identity that you use to log into Azure Databricks with Azure Active Directory Credential Passthrough. Your data access is controlled via the ADLS roles and Access Control Lists you have already set up.
Azure data factory – Seamlessly run Azure Databricks jobs using Azure Data Factory and leverage 90+ built-in data source connectors to ingest all your data sources into a single data lake. ADF provides built-in workflow control, data transformation, pipeline scheduling, data integration, and many more capabilities to help you create reliable data pipelines.
Azure synapse analytics – Azure Databricks integrates with Azure services to bring analytics, business intelligence (BI), and data science together in Microsoft’s build web and mobile applications. The high-performance connector between Azure Databricks and Azure Synapse enables fast data transfer between the services, including support for streaming data.
Power BI – One of the key features customers look for when adopting a Lakehouse strategy is the ability to efficiently and securely consume data directly from the data lake with BI tools. This typically reduces the additional latency, compute, and storage costs associated with the traditional flow of copying data already stored in a data lake to a data warehouse for BI consumption. The Azure Databricks connector in Power BI makes for a more secure, more interactive data visualization experience for data stored in your data lake.
Azure DevOps – Azure Databricks connects with Azure DevOps to help enable Continuous Integration and Continuous Deployment (CI/CD). Configure Azure DevOps as your Git provider and take advantage of the integrated version control features.
Azure virtual network – The default deployment of Azure Databricks is a fully managed service on Azure that includes a virtual network (VNet). Azure Databricks also supports deployment in your own virtual network (sometimes called VNet injection) that enables full control of network security rules.
Azure event hubs – Get insights from live streaming data by connecting Azure Event Hubs to Azure Databricks, then process messages as they arrive. With Event Hubs and Azure Databricks, stream millions of events per second from any IoT device, or logs from website clickstreams, and process it in near-real time.
Azure key vault – Manage your secrets such as keys and passwords with integration to Azure Key Vault. By default, all Azure Databricks notebooks and results are encrypted at rest with a different encryption key. If you want to own and manage the key used for encrypting your notebooks and results yourself, you can bring your own key (BYOK).
Azure confidential computing – Customers can run their Azure Databricks workloads on Azure confidential virtual machines (VMs). With support for Azure confidential computing, customers can build an end-to-end data platform on the Databricks Lakehouse with increased confidentiality and privacy by encrypting data in use. This builds on support for customer-managed keys (CMK) for encrypting data at rest.
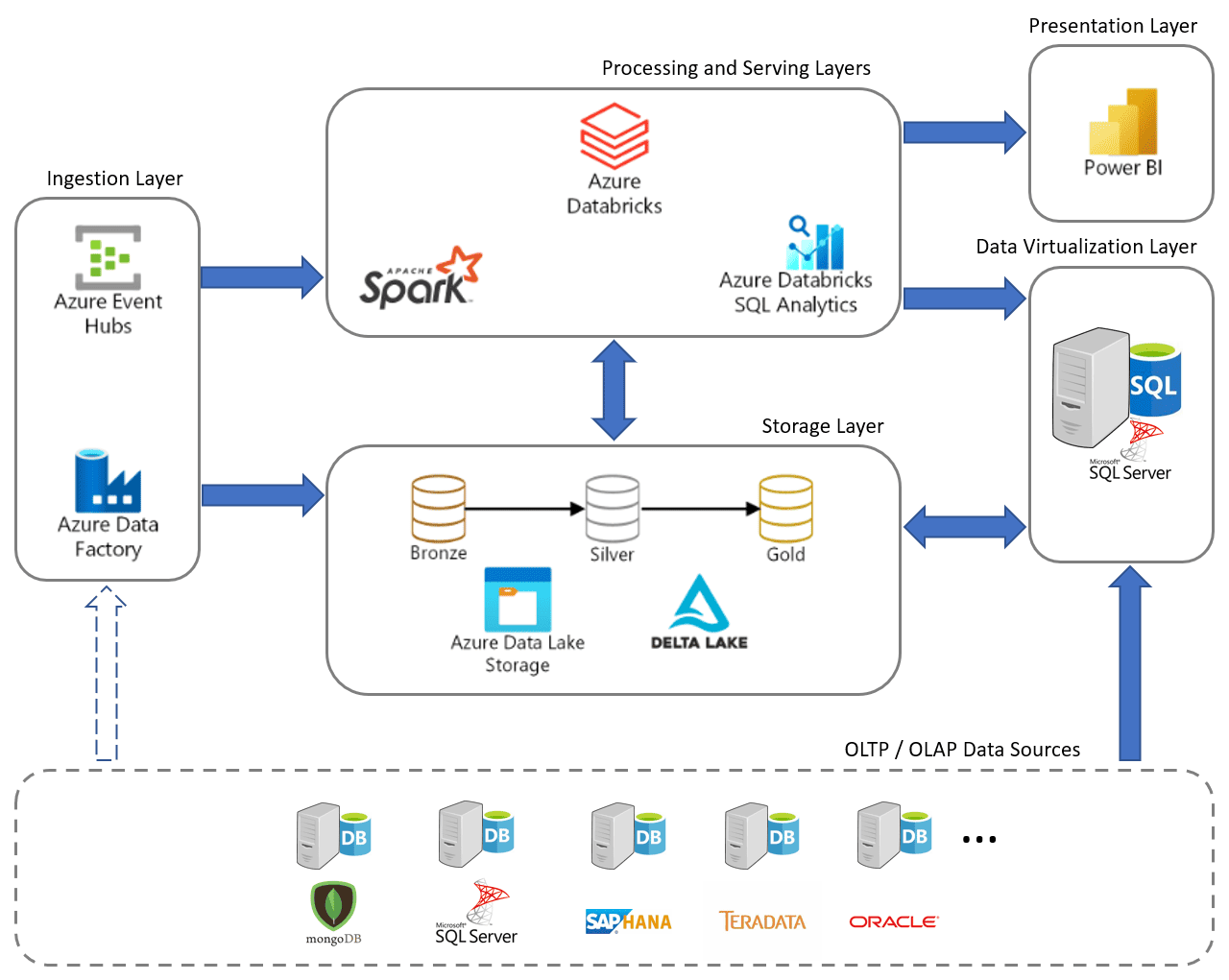

Azure Databricks Pricing
Azure Databricks pricing is based on two main components:
- Databricks Units (DBUs): DBUs are a unit of processing capability. The number of DBUs you need will depend on the size and complexity of your workloads.
- Storage costs: Azure Databricks stores data in Azure Blob Storage or Azure Data Lake Storage Gen2. You will be charged for the storage costs associated with your data.
Azure Databricks offers a variety of pricing options, including:
- Pay-as-you-go: This is the most flexible pricing option. You are charged based on the number of DBUs you use and the amount of storage you consume.
- Committed use: This pricing option can save you money if you have predictable workloads. You commit to a certain number of DBUs for a period of one or three years.
- Spot instances: Spot instances can be a cost-effective option for workloads that are not time-sensitive. Spot instances are available at a discounted price, but they can be terminated if Azure needs the capacity for other workloads.
You can use the Azure Databricks pricing calculator to estimate the cost of your Azure Databricks workloads.
Here are some tips for saving money on Azure Databricks:
- Use autoscaling: Autoscaling allows Azure Databricks to automatically scale your clusters up or down based on the demand. This can help you to save money on compute costs.
- Use managed services: Azure Databricks provides a variety of managed services, such as managed notebooks and managed streaming. These services can help you to reduce the operational overhead of managing your Azure Databricks environment.
- Use spot instances: Spot instances can be a cost-effective option for workloads that are not time-sensitive. Spot instances are available at a discounted price, but they can be terminated if Azure needs the capacity for other workloads.
Overall, Azure Databricks offers a variety of pricing options and features to help you save money.
Features
Standard Tier Features |
|||
|---|---|---|---|
| Feature | All-Purpose Compute | Jobs Compute | Jobs Light Compute |
| Interactive workloads to analyze data collaboratively with notebooks | Automated workloads to run fast and robust jobs via API or UI | Automated workloads to run robust jobs via API or UI | |
| Apache Spark on Databricks platform | Available |
Available |
Available |
| Job scheduling with libraries | Available |
Available |
Available |
| Job scheduling with Notebooks | Available |
Available |
Not available |
| Autopilot clusters | Available |
Available |
Not available |
| Databricks Runtime for ML | Available |
Available |
Not available |
| MLflow on Databricks Preview | Available |
Available |
Not available |
| Databricks Delta | Available |
Available |
Not available |
| Interactive clusters | Available |
Not available |
Not available |
| Notebooks and collaboration | Available |
Not available |
Not available |
| Ecosystem integrations | Available |
Not available |
Not available |
Premium Tier Features |
|||
| Feature | All-Purpose Compute | Jobs Compute | Jobs Light Compute |
| Interactive workloads to analyze data collaboratively with notebooks | Automated workloads to run fast and robust jobs via API or UI | Automated workloads to run robust jobs via API or UI | |
| Includes standard features | Includes standard features | Includes standard features | |
| Role-based access control for notebooks, clusters, jobs, and tables | Available |
Available |
Available |
| JDBC/ODBC Endpoint Authentication | Available |
Available |
Available |
| Audit logs | Available |
Available |
Available |
| All Standard Plan Features | Available |
Available |
Available |
| Azure AD credential passthrough | Available |
Available |
Not available |
| Conditional Authentication | Available |
Not available |
Not available |
| Cluster Policies (preview) | Available |
Available |
Available |
| IP Access List (preview) | Available |
Available |
Available |
| Token Management API (preview) | Available |
Available |
Available |
Delta Live Tables (DLT) Features |
|||
| Feature | DLT Core | DLT Pro | DLT Advanced |
| Basic Capabilities | Available |
Available |
Available |
| Change Data Capture | Not available |
Available |
Available |
| Data Quality | Not available |
Not available |
Available |
Support for Azure Databricks
First and foremost, enterprises should understand Azure Databricks includes basic Azure support only by default. You can enhance your support significantly with Unified Support for Azure or third-party support for Azure at US Cloud.
Azure Databricks support is available 24/7/365 through a variety of channels, including:
- Support portal: You can create and track support tickets through the Azure Databricks support portal.
- Chat support: You can chat with a Microsoft support engineer in real time.
- Phone support: You can call Microsoft support and speak with a support engineer.
- Community support: You can ask questions and get help from other Azure Databricks users on the Azure Databricks community forum.
The level of support you receive depends on your Azure Databricks support plan. Azure Databricks offers a variety of support plans, including:
- Basic support: Basic support is included with all Azure Databricks subscriptions. It provides access to the support portal and community support.
- Standard support: Standard support provides a higher level of support, including access to chat and phone support.
- Premium support: Premium support provides the highest level of support, including access to a dedicated support team.
You can choose the support plan that best meets your needs and budget.
To get support for Azure Databricks, you can create a support ticket through the Azure Databricks support portal or chat with a Microsoft support engineer in real time.
Here are some tips for getting the most out of Azure Databricks support with either Microsoft or US Cloud:
- Be specific: When you create a support ticket, be as specific as possible about the issue you are experiencing. This will help the support team to resolve your issue more quickly.
- Provide detailed information: The more information you can provide to the support team, the better. This may include information such as the error messages you are receiving, the code you are running, and the data you are using.
- Be responsive: The support team may need to ask you additional questions to troubleshoot your issue. Be sure to respond to their questions promptly so that they can resolve your issue as quickly as possible.
Overall, a variety of support options are available for Azure Databricks to help you get the help you need when you need it.

AZURE DATABRICKS
Azure Databricks combines data warehouses and data lakes into a lakehouse architecture. Unify all your data, analytics and AI on one platform.
What is | Architecture | Integrations | Pricing | Support
What is Azure Databricks?
Azure Databricks is a unified analytics platform that enables organizations to build data pipelines, machine learning models, and dashboards at scale. It is a fully managed service that runs on Azure, and it provides a unified workspace for data scientists, data engineers, and business analysts to collaborate on projects.
Azure Databricks is built on top of Apache Spark, a popular open-source distributed computing framework. It provides an optimized Spark environment, as well as a suite of tools and features that make it easier to build and deploy analytics and AI applications.
Azure Databricks is a popular choice for a variety of use cases, including:
- Data engineering: Azure Databricks can be used to build and manage data pipelines that process and transform large datasets.
- Machine learning: Azure Databricks provides a variety of tools and libraries for building and deploying machine learning models.
- Business intelligence: Azure Databricks can be used to create dashboards and reports that provide insights into data.
Azure Databricks is also tightly integrated with other Azure services, such as Azure Storage, Azure SQL Database, and Azure Machine Learning Studio. This makes it easy to build and deploy end-to-end analytics and AI solutions on Azure.
Here are some of the benefits of using Azure Databricks:
- Unified platform: Azure Databricks provides a single platform for data engineering, data science, and business intelligence. This makes it easier for teams to collaborate on projects and share data.
- Scalability: Azure Databricks can scale to meet the needs of the most demanding workloads. It can handle petabytes of data and thousands of concurrent users.
- Performance: Azure Databricks is optimized for performance, and it can deliver insights from data quickly and efficiently.
- Ease of use: Azure Databricks is easy to use, and it provides a variety of tools and features to help users get started quickly.
Overall, Azure Databricks is a powerful and versatile analytics platform that can be used to solve a wide range of problems. It is a good choice for organizations of all sizes that are looking to build and deploy end-to-end analytics and AI solutions.
The Best Azure Databricks Architecture
The best Azure Databricks architecture depends on the specific needs of your organization and the use cases you are planning to support. However, there are some general best practices that you can follow to design a scalable, efficient, and secure architecture.
Here are some tips for designing the best Azure Databricks architecture:
- Use a layered architecture: A layered architecture separates your data and workloads into different layers, such as a landing zone, a data lake, and a data warehouse. This makes it easier to manage your data and workloads, and it also improves performance and security.
- Use Delta Lake: Delta Lake is an open-source storage format that provides ACID transactions and other features that make it ideal for storing data in Azure Databricks. It is also compatible with Spark, so you can use existing Spark code to process and transform your data.
- Use autoscaling: Autoscaling allows Azure Databricks to automatically scale your clusters up or down based on the demand. This can help you to save money on compute costs.
- Use managed services: Azure Databricks provides a variety of managed services, such as managed notebooks and managed streaming. These services can help you to reduce the operational overhead of managing your Azure Databricks environment.
- Use security features: Azure Databricks provides a variety of security features, such as role-based access control (RBAC) and encryption. These features can help you to protect your data and workloads from unauthorized access.
Here is an example of a layered Azure Databricks architecture:
- Landing zone: The landing zone is a temporary storage area where data is first ingested into Azure Databricks. The landing zone can be stored in Azure Blob Storage or Azure Data Lake Storage Gen2.
- Data lake: The data lake is a central repository for all of your data, regardless of its format or structure. The data lake can be stored in Azure Data Lake Blob Storage or Azure Data Lake Storage Gen2.
- Data warehouse: The data warehouse is a highly optimized data store for running analytical queries and reports. The data warehouse can be stored in Azure Synapse Analytics or Azure SQL Database. See the differences between a data lake and data warehouse.
The Azure Databricks clusters can access data in the landing zone and the data lake to perform processing and transformation tasks. The processed and transformed data can then be loaded into the data warehouse for analytical purposes.
This is just one example of an Azure Databricks architecture. The specific architecture that you choose will depend on your specific needs and use cases.
Here are some additional best practices for designing an Azure Databricks architecture:
- Use a version control system: Use a version control system, such as Git, to track changes to your Azure Databricks notebooks and other code. This will make it easier to collaborate with others and to roll back changes if necessary.
- Use unit tests: Use unit tests to test your Azure Databricks code. This will help you to identify and fix bugs early on.
- Use integration tests: Use integration tests to test your Azure Databricks code with other components of your architecture, such as your data sources and data warehouse. This will help you to ensure that your entire architecture is working together as expected.
- Monitor your architecture: Monitor your Azure Databricks architecture to identify and resolve any performance or security issues. You can use Azure Databricks Monitoring to monitor your clusters and jobs.
By following these best practices, you can design an Azure Databricks architecture that is scalable, efficient, secure, and reliable.
Databricks Key Azure Integrations
Databricks offers several integrations with Azure to provide a seamless and powerful data analytics and machine learning environment. These integrations leverage the capabilities of Azure services to enhance data engineering, data science, and machine learning workflows.
Here are the major Databricks integrations with Azure:
Azure Databricks service – Azure Databricks itself is a managed Apache Spark and data analytics platform that is tightly integrated with Azure. It provides a collaborative environment for data engineers and data scientists to work together on big data and machine learning projects.
Azure blob storage – Databricks can seamlessly integrate with Azure Blob Storage, making it easy to access and process data stored in Azure Data Lake Storage or Azure Blob Storage containers. This integration allows you to read and write data efficiently, enhancing data engineering workflows.
Azure machine learning – Databricks can integrate with Azure Machine Learning services, allowing data scientists to train and deploy machine learning models using Databricks clusters and then easily deploy them to Azure for production use.
Azure monitor and Azure log analytics – Databricks can integrate with Azure Monitor and Azure Log Analytics to provide monitoring, logging, and diagnostic capabilities for your Databricks workloads. This integration helps in performance tuning and troubleshooting.
Azure active directory – Single Sign-On with Azure Active Directory is the best way to sign in to Azure Databricks. Azure Databricks also supports automated user provisioning with Azure AD to create new users, give them the proper level of access, and remove users to deprovision access.
Azure data lake storage – The Azure Databricks native connector to ADLS supports multiple methods of access to your data lake. Simplify data access security by using the same Azure AD identity that you use to log into Azure Databricks with Azure Active Directory Credential Passthrough. Your data access is controlled via the ADLS roles and Access Control Lists you have already set up.
Azure data factory – Seamlessly run Azure Databricks jobs using Azure Data Factory and leverage 90+ built-in data source connectors to ingest all your data sources into a single data lake. ADF provides built-in workflow control, data transformation, pipeline scheduling, data integration, and many more capabilities to help you create reliable data pipelines.
Azure synapse analytics – Azure Databricks integrates with Azure services to bring analytics, business intelligence (BI), and data science together in Microsoft’s build web and mobile applications. The high-performance connector between Azure Databricks and Azure Synapse enables fast data transfer between the services, including support for streaming data.
Power BI – One of the key features customers look for when adopting a Lakehouse strategy is the ability to efficiently and securely consume data directly from the data lake with BI tools. This typically reduces the additional latency, compute, and storage costs associated with the traditional flow of copying data already stored in a data lake to a data warehouse for BI consumption. The Azure Databricks connector in Power BI makes for a more secure, more interactive data visualization experience for data stored in your data lake.
Azure DevOps – Azure Databricks connects with Azure DevOps to help enable Continuous Integration and Continuous Deployment (CI/CD). Configure Azure DevOps as your Git provider and take advantage of the integrated version control features.
Azure virtual network – The default deployment of Azure Databricks is a fully managed service on Azure that includes a virtual network (VNet). Azure Databricks also supports deployment in your own virtual network (sometimes called VNet injection) that enables full control of network security rules.
Azure event hubs – Get insights from live streaming data by connecting Azure Event Hubs to Azure Databricks, then process messages as they arrive. With Event Hubs and Azure Databricks, stream millions of events per second from any IoT device, or logs from website clickstreams, and process it in near-real time.
Azure key vault – Manage your secrets such as keys and passwords with integration to Azure Key Vault. By default, all Azure Databricks notebooks and results are encrypted at rest with a different encryption key. If you want to own and manage the key used for encrypting your notebooks and results yourself, you can bring your own key (BYOK).
Azure confidential computing – Customers can run their Azure Databricks workloads on Azure confidential virtual machines (VMs). With support for Azure confidential computing, customers can build an end-to-end data platform on the Databricks Lakehouse with increased confidentiality and privacy by encrypting data in use. This builds on support for customer-managed keys (CMK) for encrypting data at rest.
Azure Databricks Pricing
Azure Databricks pricing is based on two main components:
- Databricks Units (DBUs): DBUs are a unit of processing capability. The number of DBUs you need will depend on the size and complexity of your workloads.
- Storage costs: Azure Databricks stores data in Azure Blob Storage or Azure Data Lake Storage Gen2. You will be charged for the storage costs associated with your data.
Azure Databricks offers a variety of pricing options, including:
- Pay-as-you-go: This is the most flexible pricing option. You are charged based on the number of DBUs you use and the amount of storage you consume.
- Committed use: This pricing option can save you money if you have predictable workloads. You commit to a certain number of DBUs for a period of one or three years.
- Spot instances: Spot instances can be a cost-effective option for workloads that are not time-sensitive. Spot instances are available at a discounted price, but they can be terminated if Azure needs the capacity for other workloads.
You can use the Azure Databricks pricing calculator to estimate the cost of your Azure Databricks workloads.
Here are some tips for saving money on Azure Databricks:
- Use autoscaling: Autoscaling allows Azure Databricks to automatically scale your clusters up or down based on the demand. This can help you to save money on compute costs.
- Use managed services: Azure Databricks provides a variety of managed services, such as managed notebooks and managed streaming. These services can help you to reduce the operational overhead of managing your Azure Databricks environment.
- Use spot instances: Spot instances can be a cost-effective option for workloads that are not time-sensitive. Spot instances are available at a discounted price, but they can be terminated if Azure needs the capacity for other workloads.
Overall, Azure Databricks offers a variety of pricing options and features to help you save money.
Support for Azure Databricks
First and foremost, enterprises should understand Azure Databricks includes basic Azure support only by default. You can enhance your support significantly with Unified Support for Azure or third-party support for Azure at US Cloud.
Azure Databricks support is available 24/7/365 through a variety of channels, including:
- Support portal: You can create and track support tickets through the Azure Databricks support portal.
- Chat support: You can chat with a Microsoft support engineer in real time.
- Phone support: You can call Microsoft support and speak with a support engineer.
- Community support: You can ask questions and get help from other Azure Databricks users on the Azure Databricks community forum.
The level of support you receive depends on your Azure Databricks support plan. Azure Databricks offers a variety of support plans, including:
- Basic support: Basic support is included with all Azure Databricks subscriptions. It provides access to the support portal and community support.
- Standard support: Standard support provides a higher level of support, including access to chat and phone support.
- Premium support: Premium support provides the highest level of support, including access to a dedicated support team.
You can choose the support plan that best meets your needs and budget.
To get support for Azure Databricks, you can create a support ticket through the Azure Databricks support portal or chat with a Microsoft support engineer in real time.
Here are some tips for getting the most out of Azure Databricks support with either Microsoft or US Cloud:
- Be specific: When you create a support ticket, be as specific as possible about the issue you are experiencing. This will help the support team to resolve your issue more quickly.
- Provide detailed information: The more information you can provide to the support team, the better. This may include information such as the error messages you are receiving, the code you are running, and the data you are using.
- Be responsive: The support team may need to ask you additional questions to troubleshoot your issue. Be sure to respond to their questions promptly so that they can resolve your issue as quickly as possible.
Overall, a variety of support options are available for Azure Databricks to help you get the help you need when you need it.

Microsoft Support for Federal Agencies: How to Save 30–50% Through NASA SEWP VI

Microsoft Customer Agreement vs. Enterprise Agreement: The Government Administrative-Refresh Trap

Partner-Delivered Microsoft Support: A Unified Support Alternative for Enterprises
