Data Lake vs. Data Warehouse.
DATA LAKE VS DATA WAREHOUSE
Understand the differences between data lakes and data warehouses to leverage their strengths in both for your enterprise data architecture.
Lake | Warehouse | Differences | Architecture | Support

What is a Data Lake?
A data lake is a centralized repository that stores all your data, regardless of format or size. It can store structured, semi-structured, and unstructured data, including text, images, audio, and video.
Data lakes are often used to store big data, which is data that is too large or complex to be processed by traditional database systems.
Data lakes are used for a variety of purposes, including:
- Analytics: Data lakes can be used to perform analytics on large datasets to identify trends and patterns. This information can be used to improve decision-making, optimize products and services, and develop new business opportunities.
- Machine learning: Data lakes can be used to train and deploy machine learning models. Machine learning models can be used to make predictions, identify anomalies, and automate tasks.
- Data warehousing: Data lakes can be used to create data warehouses. Data warehouses are highly optimized data stores that are designed for running analytical queries and reports.
- Data archiving: Data lakes can be used to archive data for long-term storage. Archived data can be used for compliance purposes or for future analysis.
Data lakes offer a number of benefits, including:
- Scalability: Data lakes can scale to meet the needs of the most demanding workloads. They can handle petabytes of data and thousands of concurrent users.
- Performance: Data lakes are optimized for performance, and they can deliver insights from data quickly and efficiently.
- Flexibility: Data lakes can store data in any format, so you are not limited by the schema of a traditional database.
- Cost-effectiveness: Data lakes are a cost-effective way to store and manage large datasets.
Data lakes are a powerful tool that can help organizations to get the most out of their data. However, it is important to note that data lakes can be complex and expensive to manage. Before implementing a data lake, it is important to carefully consider your needs and requirements.
Here are some examples of how data lakes are used in the real world:
- Retail: Retailers use data lakes to analyze customer purchase data to identify trends and patterns. This information can be used to improve product selection, target marketing campaigns, and optimize store layouts.
- Finance: Financial institutions use data lakes to analyze customer data, market data, and risk data to make better investment decisions and to manage risk.
- Manufacturing: Manufacturers use data lakes to analyze sensor data from machines to predict maintenance needs and to improve product quality.
- Healthcare: Healthcare organizations use data lakes to analyze patient data, clinical trial data, and research data to improve patient care and to develop new drugs and treatments.
Data lakes are a powerful big data tool that can be used by enterprises to get the most out of their data.
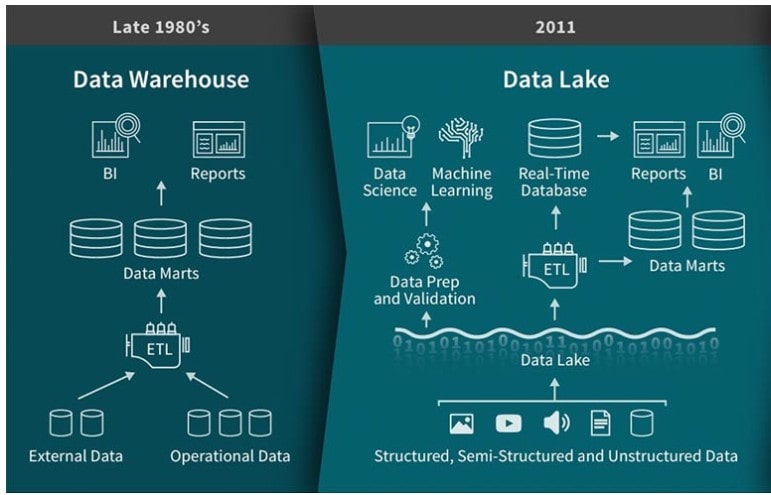
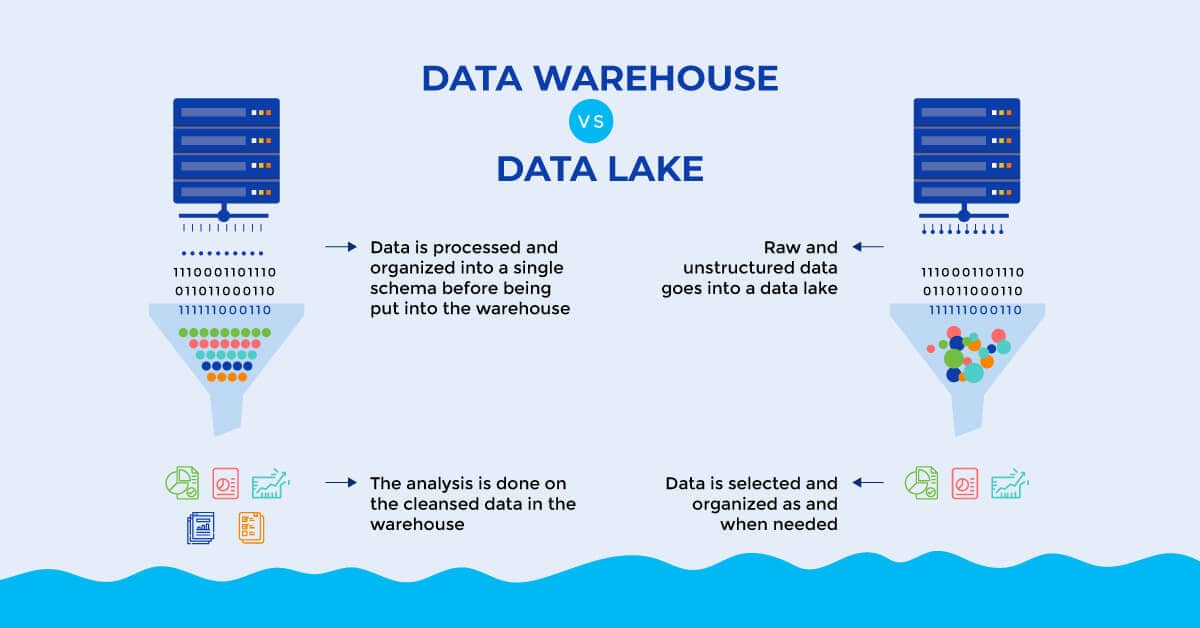
What is a Data Warehouse?
A data warehouse is a system used for reporting and data analysis. It is a central repository of data that has been integrated from multiple sources and transformed into a format that is optimized for query and analysis.
Data warehouses are typically used to store historical data, but they can also be used to store real-time data.
Data warehouses are used for a variety of purposes, including:
- Business intelligence (BI): Data warehouses are used to create BI reports and dashboards that provide insights into business performance.
- Analytics: Data warehouses are used to perform analytics on large datasets to identify trends and patterns. This information can be used to improve decision-making, optimize products and services, and develop new business opportunities.
- Machine learning: Data warehouses can be used to train and deploy machine learning models. Machine learning models can be used to make predictions, identify anomalies, and automate tasks.
Data warehouses offer a number of benefits, including:
- Performance: Data warehouses are optimized for performance, and they can deliver insights from data quickly and efficiently.
- Scalability: Data warehouses can scale to meet the needs of the most demanding workloads. They can handle petabytes of data and thousands of concurrent users.
- Reliability: Data warehouses are designed to be reliable and to provide high availability.
- Security: Data warehouses provide a variety of security features to protect data from unauthorized access.
Data warehouses are a powerful tool that can help organizations to get the most out of their data. However, it is important to note that data warehouses can be complex and expensive to implement and maintain. Before implementing a data warehouse, it is important to carefully consider your needs and requirements.
Here are some examples of how data warehouses are used in the real world:
- Retail: Retailers use data warehouses to analyze customer purchase data to identify trends and patterns. This information can be used to improve product selection, target marketing campaigns, and optimize store layouts.
- Finance: Financial institutions use data warehouses to analyze customer data, market data, and risk data to make better investment decisions and to manage risk.
- Manufacturing: Manufacturers use data warehouses to analyze sensor data from machines to predict maintenance needs and to improve product quality.
- Healthcare: Healthcare organizations use data warehouses to analyze patient data, clinical trial data, and research data to improve patient care and to develop new drugs and treatments.
Overall, data warehouses are a powerful tool that can be used by companies of all sizes to get the most out of their ever-growing data.
Data Lake vs. Data Warehouse
Data lakes and data warehouses are both data storage and processing solutions, but they have distinct characteristics and are designed for different purposes.
Here are the key differences between data lakes and data warehouses:
Data Type and Structure
Data Lake: Data lakes can store structured, semi-structured, and unstructured data. They are highly flexible and can accommodate raw, diverse data formats, including text, images, videos, logs, and more, without the need for a predefined schema.
Data Warehouse: Data warehouses primarily store structured data with well-defined schemas. They require data to be pre-processed and structured before ingestion, making them less flexible when dealing with unstructured or semi-structured data.
Schema
Data Lake: Data lakes typically use a schema-on-read approach. The schema is applied when data is read or processed, allowing for schema flexibility and accommodating changes in data over time.
Data Warehouse: Data warehouses use a schema-on-write approach. Data must be transformed and structured into a predefined schema before it is loaded into the warehouse. Any changes to the schema can be complex and time-consuming.
Data Integration
Data Lake: Data lakes are designed for data integration, allowing you to ingest and consolidate data from various sources without significant preprocessing. Integration often involves ETL (Extract, Transform, Load) processes.
Data Warehouse: Data warehouses also integrate data from multiple sources but require data to be transformed and cleaned before loading, which is typically done as part of the ETL process.
Data Storage
Data Lake: Data lakes are typically more cost-effective for storing large volumes of raw data, making them suitable for storing vast amounts of data at a lower cost per terabyte.
Data Warehouse: Data warehouses are optimized for query performance and are more expensive to scale for large data volumes. They are ideal for storing structured data that requires fast and efficient querying.
Data Processing
Data Lake: Data lakes are versatile and can handle various data processing tasks, including batch processing, real-time processing, and machine learning, using tools like Azure Data Lake Analytics or Apache Spark.
Data Warehouse: Data warehouses are primarily designed for complex SQL-based querying and reporting, making them suitable for business intelligence and analytics workloads.
User Access and Tools
Data Lake: Data lakes are often used by data engineers, data scientists, and analysts who need to explore and analyze raw or semi-structured data. A variety of tools and languages, including Python and SQL, are used for data processing and analysis.
Data Warehouse: Data warehouses are primarily used by business analysts, data analysts, and decision-makers for structured data analysis. They typically rely on SQL-based reporting tools and business intelligence platforms.
Use Cases
Data Lake: Data lakes are ideal for data exploration, data science, big data analytics, and storing massive volumes of raw data. They are suited for scenarios where data needs to be ingested rapidly from various sources.
Data Warehouse: Data warehouses excel in providing fast, reliable, and structured data for business reporting, dashboarding, and ad-hoc queries. They are used for structured data analysis and historical reporting.
It’s important to note that many organizations use both data lakes and data warehouses in their data architecture to leverage the strengths of each approach. This combination allows for flexibility, scalability, and the ability to handle a wide range of data processing and analysis requirements.
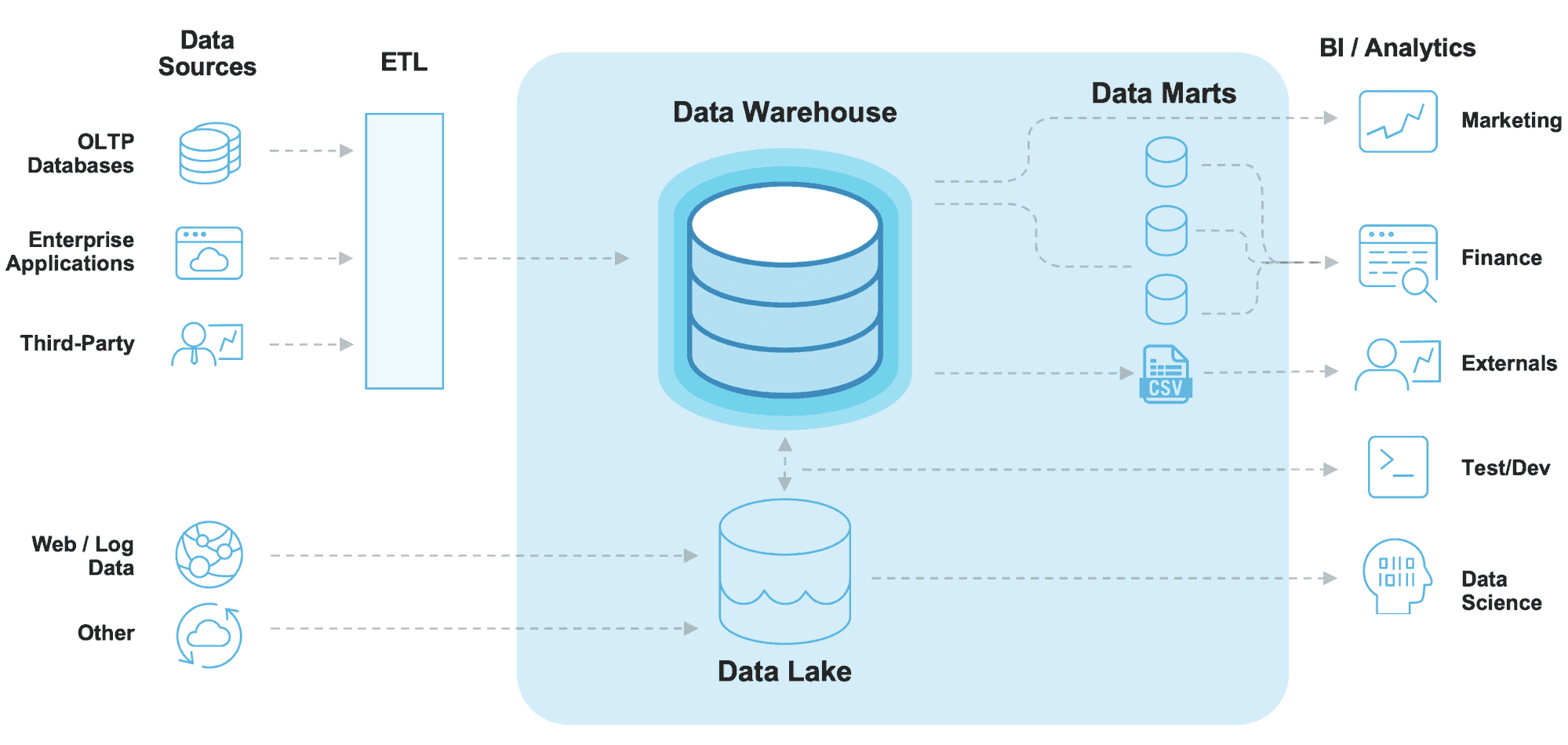

Data Lake vs. Data Warehouse Architecture
Data lakes and data warehouses are both important tools for data storage and analysis, but they have different architectures and use cases.
Data lake architecture
- Data lakes are designed to store all of an organization’s data, regardless of format or structure. This makes them ideal for storing big data and unstructured data.
- Data lakes typically have a schema-on-read architecture, which means that the data is not structured until it is read into an application. This makes data lakes flexible and scalable, but it can also make them more difficult to query and analyze.
- Data lakes are often used for exploratory data analysis and machine learning.
Data warehouse architecture
- Data warehouses are designed to store structured data that has been cleaned and processed. This makes them ideal for reporting and analytics.
- Data warehouses typically have a schema-on-write architecture, which means that the data is structured when it is loaded into the Azure data warehouse. This makes data warehouses faster and easier to query and analyze, but it can also make them less flexible and scalable.
- Data warehouses are often used for business intelligence and decision support systems.
Which one to choose?
The best choice for your organization will depend on your specific needs and requirements. If you need to store and analyze large amounts of unstructured or semi-structured data, then a data lake is a good choice. If you need to store and analyze structured data for reporting and analytics, then a data warehouse is a good choice.
In some cases, organizations may choose to use both a data lake and a data warehouse together. The data lake can be used to store all of the organization’s data, and the data warehouse can be used to store the subset of data that is needed for reporting and analytics.
Data lakes and data warehouses are both powerful tools for data storage and analysis. The best choice for your enterprise will depend on your specific needs and requirements.
Here is a table that summarizes the key differences in architecture between data lakes and data warehouses:
| Characteristic | Data lake | Data warehouse |
|---|---|---|
| Data structure | Unstructured, semi-structured, structured | Structured |
| Schema | Schema-on-read | Schema-on-write |
| Performance | Slower | Faster |
| Scalability | More scalable | Less scalable |
| Flexibility | More flexible | Less flexible |
| Use cases | Exploratory data analysis, machine learning | Reporting, analytics, business intelligence |

Support for Data Lakes and Data Warehouses
First and foremost, enterprises should understand that cloud-based data lakes and data warehouses typically include basic Azure/AWS/GC support only by default. You can enhance your support significantly with premium OEM or third-party support.
For example let’s look at Microsoft: Azure Data Lake and Data Warehouse support is available 24/7/365 through a variety of channels, including:
- Support portal: You can create and track support tickets through the Azure Data Lake/Data Warehouse support portal.
- Chat support: You can chat with a Microsoft support engineer in real time.
- Phone support: You can call Microsoft support and speak with a support engineer.
- Community support: You can ask questions and get help from other Azure Data Lake/Data Warehouse users on the Azure Data Lake/Data Warehouse community forums.
The level of support you receive depends on your Azure Data Lake/Data Warehouse support plan. Azure Data Lake/Data Warehouse offers a variety of support plans, including:
- Basic support: Basic support is included with all Azure Data Lake/Data Warehouse subscriptions. It provides access to the support portal and community support.
- Standard support: Standard support provides a higher level of support, including access to chat and phone support.
- Premium support: Premium support provides the highest level of support, including access to a dedicated support team. Extend further with Unified Support or US Cloud.
You can choose the support plan that best meets your needs and budget.
To get support for Azure Data Lake/Data Warehouse, you can create a support ticket through the Azure Databricks support portal or chat with a Microsoft support engineer in real time.
Here are some tips for getting the most out of Azure Data Lake/Data Warehouse support with either Microsoft or US Cloud:
- Be specific: When you create a support ticket, be as specific as possible about the issue you are experiencing. This will help the support team to resolve your issue more quickly.
- Provide detailed information: The more information you can provide to the support team, the better. This may include information such as the error messages you are receiving, the code you are running, and the data you are using.
- Be responsive: The support team may need to ask you additional questions to troubleshoot your issue. Be sure to respond to their questions promptly so that they can resolve your issue as quickly as possible.
Overall, a variety of support options are available for Azure Data Lake/Data Warehouse to help you get the help you need when you need it.

Microsoft Support for Federal Agencies: How to Save 30–50% Through NASA SEWP VI

Microsoft Customer Agreement vs. Enterprise Agreement: The Government Administrative-Refresh Trap

Partner-Delivered Microsoft Support: A Unified Support Alternative for Enterprises
