Azure Databricks

Azure Databricksとは何ですか?
Azure Databricksは、組織がデータパイプライン、機械学習モデル、ダッシュボードを大規模に構築できる統合分析プラットフォームです。Azure上で動作するフルマネージドサービスであり、データサイエンティスト、データエンジニア、ビジネスアナリストがプロジェクトで共同作業するための統合ワークスペースを提供します。
Azure Databricksは、人気のオープンソース分散コンピューティングフレームワークであるApache Sparkを基盤として構築されています。最適化されたSpark環境に加え、分析およびAIアプリケーションの構築とデプロイを容易にする一連のツールと機能を提供します。
Azure Databricksは、以下のような様々なユースケースで広く利用されています:
- データエンジニアリング:Azure Databricksは、大規模なデータセットを処理・変換するデータパイプラインの構築と管理に使用できます。
- 機械学習:Azure Databricksは、機械学習モデルの構築とデプロイのための様々なツールとライブラリを提供します。
- ビジネスインテリジェンス:Azure Databricksは、データに関する洞察を提供するダッシュボードやレポートの作成に使用できます。
Azure Databricksは、Azure Storage、Azure SQL Database、Azure Machine Learning Studioなどの他のAzureサービスとも緊密に連携しています。これにより、Azure上でエンドツーエンドの分析およびAIソリューションを容易に構築・展開できます。
Azure Databricks を使用するメリットの一部を以下に示します:
- 統合プラットフォーム:Azure Databricksは、データエンジニアリング、データサイエンス、ビジネスインテリジェンスのための単一プラットフォームを提供します。これにより、チームがプロジェクトで協力し、データを共有することが容易になります。
- スケーラビリティ:Azure Databricksは、最も要求の厳しいワークロードのニーズに対応できるよう拡張可能です。ペタバイト規模のデータと数千の同時ユーザーを処理できます。
- パフォーマンス:Azure Databricksはパフォーマンスに最適化されており、データから迅速かつ効率的にインサイトを提供できます。
- 使いやすさ:Azure Databricksは使いやすく、ユーザーがすぐに始められるよう、様々なツールや機能を提供しています。
全体として、Azure Databricksは強力かつ多機能な分析プラットフォームであり、幅広い課題の解決に活用できます。エンドツーエンドの分析およびAIソリューションの構築と展開を目指すあらゆる規模の組織にとって優れた選択肢です。
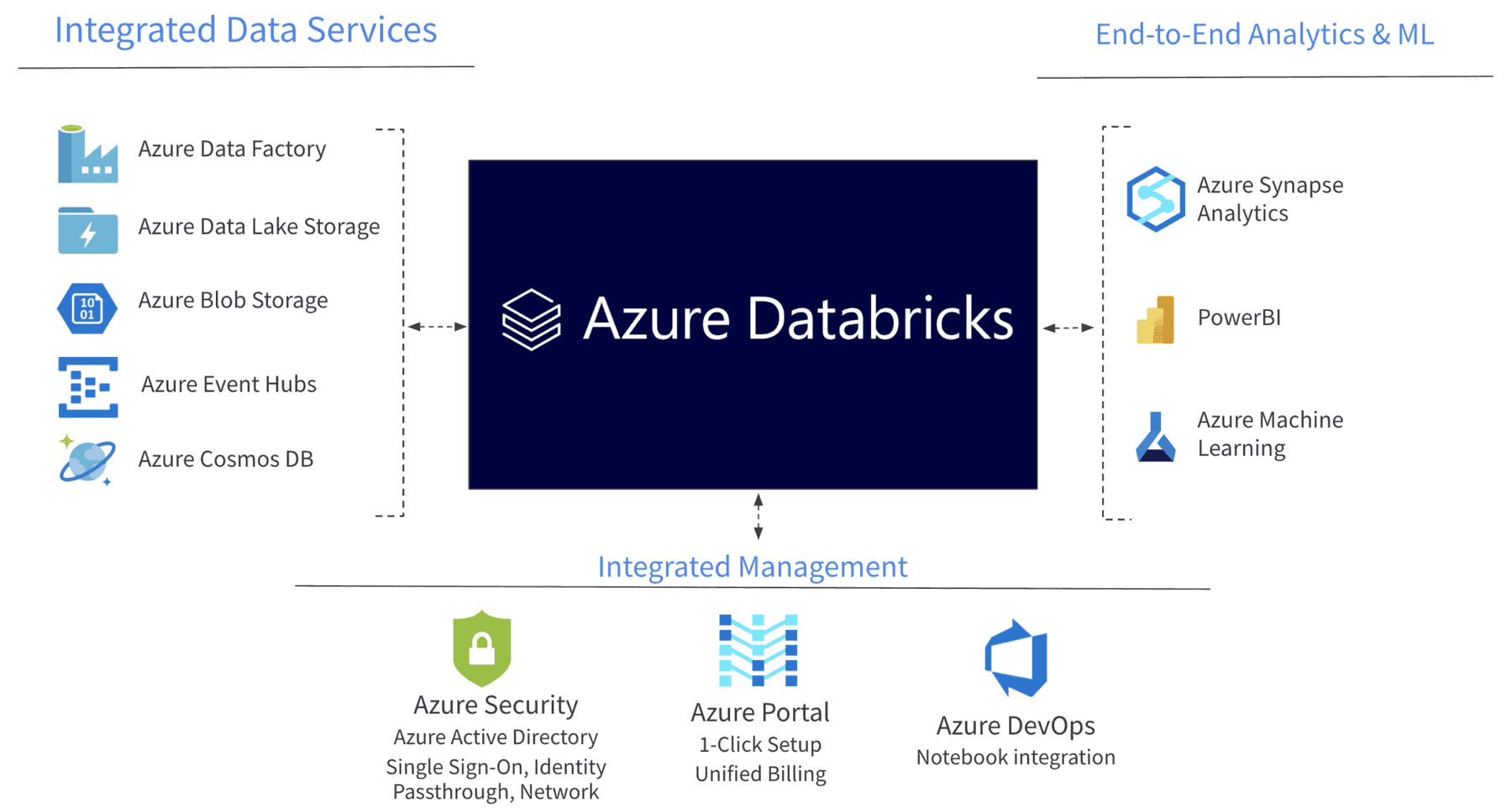
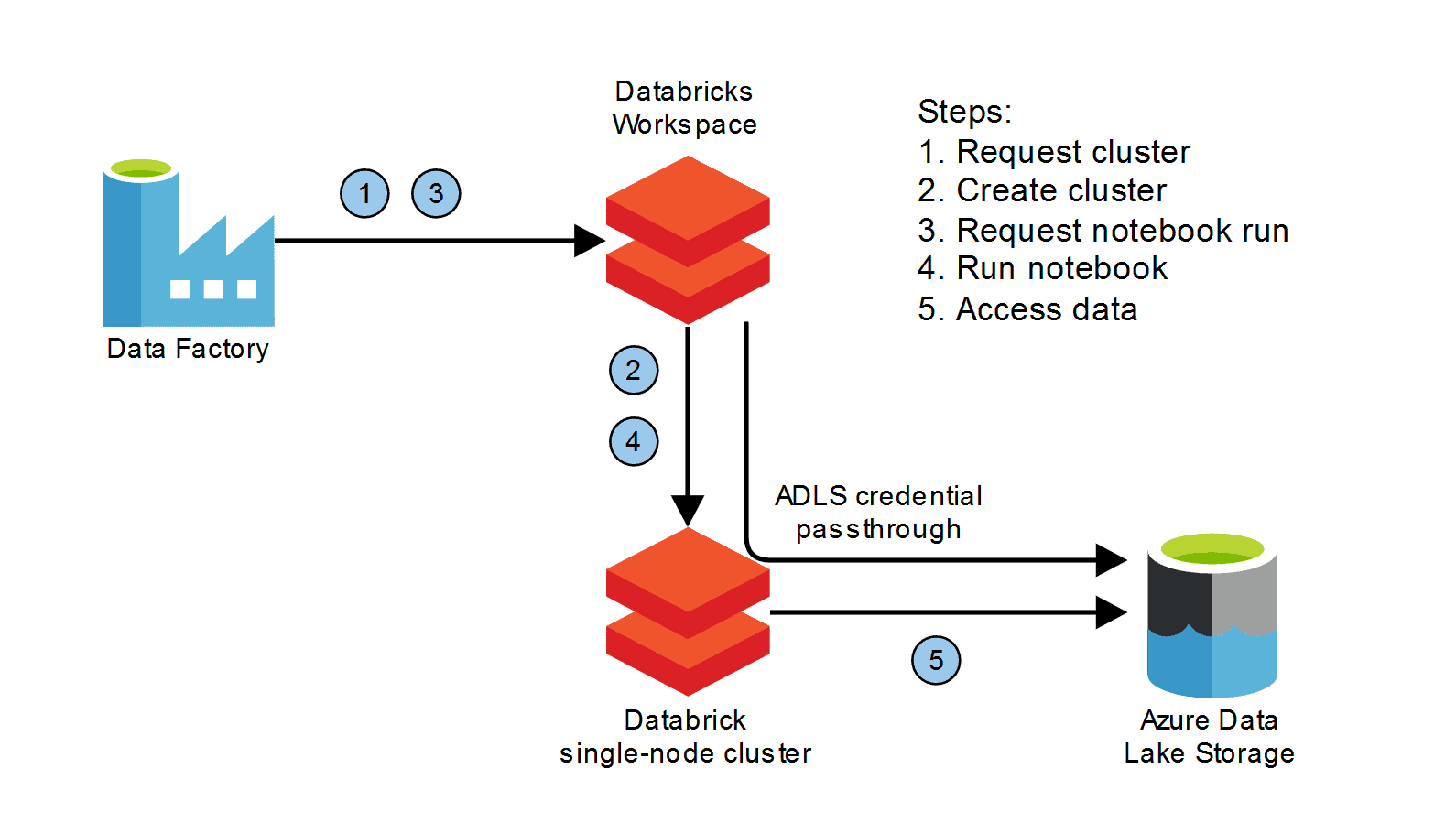
最適なAzure Databricksアーキテクチャ
最適なAzure Databricksアーキテクチャは、組織の具体的なニーズとサポート予定のユースケースによって異なります。ただし、スケーラブルで効率的かつ安全なアーキテクチャを設計するために従うべき一般的なベストプラクティスがあります。
Azure Databricksの最適なアーキテクチャ設計に関するヒントを以下に示します:
- 階層型アーキテクチャを採用する:階層型アーキテクチャでは、データとワークロードをランディングゾーン、データレイク、データウェアハウスなどの異なる層に分離します。これにより、データとワークロードの管理が容易になるだけでなく、パフォーマンスとセキュリティも向上します。
- Delta Lakeの使用:Delta Lakeはオープンソースのストレージ形式であり、ACIDトランザクションやその他の機能を提供するため、Azure Databricksでのデータ保存に最適です。またSparkと互換性があるため、既存のSparkコードを使用してデータの処理や変換を行うことができます。
- オートスケーリングを使用する:オートスケーリングにより、Azure Databricks は需要に基づいてクラスターを自動的にスケールアップまたはスケールダウンできます。これにより、コンピューティングコストの削減が可能になります。
- マネージドサービスを利用:Azure Databricksは、マネージドノートブックやマネージドストリーミングなど、さまざまなマネージドサービスを提供します。これらのサービスは、Azure Databricks環境の管理に伴う運用上の負担を軽減するのに役立ちます。
- セキュリティ機能の利用:Azure Databricksは、ロールベースのアクセス制御(RBAC)や暗号化など、さまざまなセキュリティ機能を提供します。これらの機能は、データやワークロードを不正アクセスから保護するのに役立ちます。
以下は、階層化された Azure Databricks アーキテクチャの例です:
- ランディングゾーン:ランディングゾーンは、データが最初に Azure Databricks に取り込まれる一時的な保存領域です。ランディングゾーンは Azure Blob Storage または Azure Data Lake Storage Gen2 に保存できます。
- データレイク:データレイクは、形式や構造に関わらず、すべてのデータを一元的に保管するリポジトリです。データレイクは Azure Data Lake Blob Storage または Azure Data Lake Storage Gen2 に保存できます。
- データウェアハウス:データウェアハウスは、分析クエリやレポートの実行向けに高度に最適化されたデータストアです。 Azure データウェアハウス はAzure Synapse AnalyticsまたはAzure SQL Databaseに保存できます。データレイクとデータウェアハウスの違いを参照してください。
Azure Databricksクラスターは、ランディングゾーンとデータレイク内のデータにアクセスして、処理および変換タスクを実行できます。処理および変換されたデータは、分析目的でデータウェアハウスにロードできます。
これはAzure Databricksアーキテクチャの一例に過ぎません。選択する具体的なアーキテクチャは、お客様の特定のニーズとユースケースによって異なります。
Azure Databricks アーキテクチャ設計に関する追加のベストプラクティスを以下に示します:
- バージョン管理システムを使用する:Gitなどのバージョン管理システムを使用して、Azure Databricksノートブックやその他のコードの変更を追跡します。これにより、他のユーザーとの共同作業が容易になり、必要に応じて変更をロールバックできるようになります。
- ユニットテストを使用する:Azure Databricks コードのテストにはユニットテストを使用してください。これにより、バグを早期に特定し修正することが可能になります。
- 統合テストを使用する:Azure Databricks コードを、データソースやデータウェアハウスなど、アーキテクチャの他のコンポーネントと組み合わせてテストするために統合テストを使用します。これにより、アーキテクチャ全体が期待通りに連携していることを確認できます。
- アーキテクチャの監視:Azure Databricks アーキテクチャを監視し、パフォーマンスやセキュリティの問題を特定して解決します。Azure Databricks Monitoring を使用してクラスターやジョブを監視できます。
これらのベストプラクティスに従うことで、スケーラブルで効率的、かつ安全で信頼性の高い Azure Databricks アーキテクチャを設計できます。
Databricksの主要なAzure統合
Databricksは、シームレスで強力なデータ分析および機械学習環境を提供するため、Azureとの複数の連携機能を提供しています。これらの連携はAzureサービスの機能を活用し、データエンジニアリング、データサイエンス、機械学習のワークフローを強化します。
DatabricksとAzureの主な統合機能は以下の通りです:
Azure Databricks サービス– Azure Databricks 自体は、Azure と緊密に統合されたマネージドの Apache Spark およびデータ分析プラットフォームです。データエンジニアとデータサイエンティストがビッグデータおよび機械学習プロジェクトで共同作業を行うためのコラボレーション環境を提供します。
Azure Blob Storage– DatabricksはAzure Blob Storageとシームレスに連携し、Azure Data Lake StorageまたはAzure Blob Storageコンテナに保存されたデータへのアクセスと処理を容易にします。この連携により、データを効率的に読み書きでき、データエンジニアリングワークフローが強化されます。
Azure Machine Learning– DatabricksはAzure Machine Learningサービスと連携可能であり、データサイエンティストはDatabricksクラスターを使用して機械学習モデルのトレーニングとデプロイを行い、その後簡単にAzureにデプロイして本番環境で使用できます。
Azure Monitor と Azure Log Analytics– Databricks は Azure Monitor および Azure Log Analytics と連携し、Databricks ワークロード向けの監視、ロギング、診断機能を提供します。この連携により、パフォーマンス調整やトラブルシューティングが容易になります。
Azure Active Directory– Azure Active Directory を使用したシングルサインオンは、Azure Databricks にサインインする最適な方法です。Azure Databricks は Azure AD との連携による自動ユーザープロビジョニングもサポートしており、新規ユーザーの作成、適切なアクセス権限の付与、アクセス権限の解除を伴うユーザーの削除が可能です。
Azure データ レイク ストレージ– Azure Databricks の ADLS ネイティブ コネクタは、データ レイクへの複数のアクセス方法をサポートします。Azure Active Directory 資格情報パススルーを使用し、Azure Databricks へのログインに使用する Azure AD 同一性情報と同じものを活用することで、データ アクセス セキュリティを簡素化できます。データ アクセスは、既に設定済みの ADLS ロールとアクセス制御リスト (ACL) を通じて制御されます。
Azure Data Factory– Azure Data Factoryを使用してAzure Databricksジョブをシームレスに実行し、90以上の組み込みデータソースコネクタを活用して、すべてのデータソースを単一のデータレイクに取り込みます。ADFは、信頼性の高いデータパイプラインの構築を支援するため、組み込みのワークフロー制御、データ変換、パイプラインスケジューリング、データ統合など、多くの機能を提供します。
Azure Synapse Analytics– Azure DatabricksはAzureサービスと連携し、MicrosoftのWebおよびモバイルアプリケーション構築において、分析、ビジネスインテリジェンス(BI)、データサイエンスを統合します。Azure DatabricksとAzure Synapse間の高性能コネクタにより、ストリーミングデータのサポートを含むサービス間の高速データ転送が実現されます。
Power BI– レイクハウス戦略を採用する際に顧客が求める主要機能の一つは、BIツールを用いてデータレイクから直接データを効率的かつ安全に消費する能力です。これにより、従来のようにデータレイクに保存済みのデータをBI利用のためにデータウェアハウスへコピーするフローに伴う追加のレイテンシ、コンピューティング、ストレージコストを削減できます。 Power BIのAzure Databricksコネクタは、データレイクに保存されたデータに対して、より安全でインタラクティブなデータ可視化体験を実現します。
Azure DevOps– Azure DatabricksはAzure DevOpsと連携し、継続的インテグレーションおよび継続的デプロイメント(CI/CD)を実現します。Azure DevOpsをGitプロバイダーとして設定し、統合されたバージョン管理機能を活用してください。
Azure 仮想ネットワーク– Azure Databricks のデフォルトのデプロイは、仮想ネットワーク (VNet) を含む Azure 上の完全管理サービスです。Azure Databricks は、ネットワークセキュリティルールを完全に制御できる、お客様自身の仮想ネットワーク内でのデプロイ(VNet インジェクションとも呼ばれる)もサポートしています。
Azure Event Hubs– Azure Event Hubs を Azure Databricks に接続し、到着したメッセージを処理することで、ライブストリーミングデータからインサイトを取得します。Event Hubs と Azure Databricks を使用すれば、あらゆる IoT デバイスからの毎秒数百万件のイベントや、Web サイトのクリックストリームログをストリーミングし、ほぼリアルタイムで処理できます。
Azure Key Vault– Azure Key Vaultとの統合により、キーやパスワードなどのシークレットを管理します。デフォルトでは、すべてのAzure Databricksノートブックと結果は、異なる暗号化キーで保存時に暗号化されます。ノートブックと結果の暗号化に使用するキーを自身で所有・管理したい場合は、BYOK(Bring Your Own Key)を利用できます。
Azure機密コンピューティング– お客様はAzure機密仮想マシン(VM)上でAzure Databricksワークロードを実行できます。Azure機密コンピューティングのサポートにより、お客様は使用中のデータを暗号化することで機密性とプライバシーを強化した、Databricks Lakehouse上のエンドツーエンドデータプラットフォームを構築できます。これは、保存中のデータを暗号化するための顧客管理キー(CMK)のサポートを基盤としています。

Azure Databricks の価格
Azure Databricksの料金体系は、主に2つの要素に基づいています:
- Databricks Units (DBU):DBUは処理能力の単位です。必要なDBUの数は、ワークロードの規模と複雑さに依存します。
- ストレージ費用:Azure Databricks はデータを Azure Blob Storage または Azure Data Lake Storage Gen2 に保存します。お客様のデータに関連するストレージ費用が課金されます。
Azure Databricksでは、以下の料金プランを含む様々なオプションを提供しています:
- 従量課金制:これは最も柔軟な料金オプションです。ご利用のDBU数と消費ストレージ量に基づいて課金されます。
- コミットメント利用:予測可能なワークロードがある場合、この価格オプションでコスト削減が可能です。1年または3年の期間において、一定数のDBUをコミットします。
- スポットインスタンス:時間的制約のないワークロードには、コスト効率の高い選択肢となる場合があります。スポットインスタンスは割引価格で利用可能ですが、Azureが他のワークロードのためにその容量を必要とする場合、終了される可能性があります。
Azure Databricks のワークロードのコストを見積もるには、Azure Databricks の価格計算ツールをご利用いただけます。
Azure Databricksでコストを節約するためのヒントをいくつかご紹介します:
- オートスケーリングを使用する:オートスケーリングにより、Azure Databricks は需要に基づいてクラスターを自動的にスケールアップまたはスケールダウンできます。これにより、コンピューティングコストの削減が可能になります。
- マネージドサービスを利用:Azure Databricksは、マネージドノートブックやマネージドストリーミングなど、さまざまなマネージドサービスを提供します。これらのサービスは、Azure Databricks環境の管理に伴う運用上の負担を軽減するのに役立ちます。
- スポットインスタンスの利用:時間的制約のないワークロードには、コスト効率の高い選択肢としてスポットインスタンスが利用できます。スポットインスタンスは割引価格で提供されますが、Azureが他のワークロードのためにその容量を必要とする場合、強制終了される可能性があります。
全体として、Azure Databricksはコスト削減に役立つ多様な価格オプションと機能を提供します。
特徴
スタンダードティア機能 |
|||
|---|---|---|---|
| 機能 | 汎用コンピューティング | ジョブズ・コンピューティング | ジョブ ライト コンピューティング |
| インタラクティブなワークロードでノートブックを用いた共同データ分析 | 自動化されたワークロードにより、APIまたはUI経由で高速かつ堅牢なジョブを実行 | APIまたはUIを介して堅牢なジョブを実行する自動化されたワークロード | |
| Databricksプラットフォーム上のApache Spark | 利用可能 |
利用可能 |
利用可能 |
| ライブラリを用いたジョブスケジューリング | 利用可能 |
利用可能 |
利用可能 |
| ノートブックを用いたジョブスケジューリング | 利用可能 |
利用可能 |
利用不可 |
| オートパイロットクラスター | 利用可能 |
利用可能 |
利用不可 |
| Databricks MLランタイム | 利用可能 |
利用可能 |
利用不可 |
| Databricks上のMLflowプレビュー | 利用可能 |
利用可能 |
利用不可 |
| Databricks Delta | 利用可能 |
利用可能 |
利用不可 |
| インタラクティブクラスター | 利用可能 |
利用不可 |
利用不可 |
| ノートブックとコラボレーション | 利用可能 |
利用不可 |
利用不可 |
| エコシステム統合 | 利用可能 |
利用不可 |
利用不可 |
プレミアムティア機能 |
|||
| 機能 | 汎用コンピューティング | ジョブズ・コンピューティング | ジョブ ライト コンピューティング |
| インタラクティブなワークロードでノートブックを用いた共同データ分析 | 自動化されたワークロードにより、APIまたはUI経由で高速かつ堅牢なジョブを実行 | APIまたはUIを介して堅牢なジョブを実行する自動化されたワークロード | |
| 標準機能を含む | 標準機能を含む | 標準機能を含む | |
| ノートブック、クラスター、ジョブ、およびテーブルに対するロールベースのアクセス制御 | 利用可能 |
利用可能 |
利用可能 |
| JDBC/ODBC エンドポイント認証 | 利用可能 |
利用可能 |
利用可能 |
| 監査ログ | 利用可能 |
利用可能 |
利用可能 |
| スタンダードプランの全機能 | 利用可能 |
利用可能 |
利用可能 |
| Azure AD クレデンシャルパススルー | 利用可能 |
利用可能 |
利用不可 |
| 条件付き認証 | 利用可能 |
利用不可 |
利用不可 |
| クラスターポリシー(プレビュー) | 利用可能 |
利用可能 |
利用可能 |
| IPアクセスリスト(プレビュー) | 利用可能 |
利用可能 |
利用可能 |
| トークン管理API(プレビュー) | 利用可能 |
利用可能 |
利用可能 |
デルタライブテーブル(DLT)の特徴 |
|||
| 機能 | DLTコア | DLT Pro | DLT アドバンスト |
| 基本機能 | 利用可能 |
利用可能 |
利用可能 |
| 変更データキャプチャ | 利用不可 |
利用可能 |
利用可能 |
| データ品質 | 利用不可 |
利用不可 |
利用可能 |
Azure Databricks のサポート
まず第一に、企業はAzure Databricksがデフォルトでは基本的なAzureサポートのみを含むことを理解すべきです。Azure向け統合サポートまたはUS Cloudにおけるサードパーティ製Azureサポートを利用することで、サポートを大幅に強化できます。
Azure Databricksのサポートは、以下のさまざまなチャネルを通じて年中無休でご利用いただけます:
- サポートポータル:Azure Databricks サポートポータルを通じてサポートチケットを作成および追跡できます。
- チャットサポート:Microsoftのサポートエンジニアとリアルタイムでチャットできます。
- 電話サポート:マイクロソフトのサポートに電話し、サポートエンジニアと話すことができます。
- コミュニティサポート:Azure Databricks コミュニティフォーラムで、他の Azure Databricks ユーザーに質問したり、助けを得たりできます。
ご利用いただけるサポートのレベルは、Azure Databricksのサポートプランによって異なります。Azure Databricksでは、以下のサポートプランを含む様々なプランを提供しています:
- 基本サポート:Azure Databricks のすべてのサブスクリプションには基本サポートが含まれます。サポートポータルとコミュニティサポートへのアクセスを提供します。
- 標準サポート:標準サポートは、チャットおよび電話サポートへのアクセスを含む、より高度なサポートを提供します。
- プレミアムサポート:プレミアムサポートは最高レベルのサポートを提供し、専任サポートチームへのアクセスを含みます。
ご自身のニーズと予算に最も合ったサポートプランをお選びいただけます。
Azure Databricksのサポートを受けるには、Azure Databricksサポートポータルからサポートチケットを作成するか、Microsoftサポートエンジニアとリアルタイムでチャットできます。
MicrosoftまたはUS Cloudのいずれかを利用する場合、Azure Databricksサポートを最大限に活用するためのヒントを以下に示します:
- 具体的に:サポートチケットを作成する際は、発生している問題について可能な限り具体的に記載してください。これによりサポートチームが問題をより迅速に解決できます。
- 詳細な情報を提供してください:サポートチームに提供できる情報が多ければ多いほど、対応がスムーズになります。これには、表示されているエラーメッセージ、実行中のコード、使用しているデータなどの情報が含まれます。
- 迅速に対応してください:サポートチームは問題解決のため、追加の質問をさせていただく場合があります。問題が迅速に解決されるよう、質問には必ず速やかにご回答ください。
全体として、Azure Databricksでは多様なサポートオプションが用意されており、必要な時に必要な支援を得られるよう支援します。

Azure Databricksとは何ですか?
Azure Databricksは、組織がデータパイプライン、機械学習モデル、ダッシュボードを大規模に構築できる統合分析プラットフォームです。Azure上で動作するフルマネージドサービスであり、データサイエンティスト、データエンジニア、ビジネスアナリストがプロジェクトで共同作業するための統合ワークスペースを提供します。
Azure Databricksは、人気のオープンソース分散コンピューティングフレームワークであるApache Sparkを基盤として構築されています。最適化されたSpark環境に加え、分析およびAIアプリケーションの構築とデプロイを容易にする一連のツールと機能を提供します。
Azure Databricksは、以下のような様々なユースケースで広く利用されています:
- データエンジニアリング:Azure Databricksは、大規模なデータセットを処理・変換するデータパイプラインの構築と管理に使用できます。
- 機械学習:Azure Databricksは、機械学習モデルの構築とデプロイのための様々なツールとライブラリを提供します。
- ビジネスインテリジェンス:Azure Databricksは、データに関する洞察を提供するダッシュボードやレポートの作成に使用できます。
Azure Databricksは、Azure Storage、Azure SQL Database、Azure Machine Learning Studioなどの他のAzureサービスとも緊密に連携しています。これにより、Azure上でエンドツーエンドの分析およびAIソリューションを容易に構築・展開できます。
Azure Databricks を使用するメリットの一部を以下に示します:
- 統合プラットフォーム:Azure Databricksは、データエンジニアリング、データサイエンス、ビジネスインテリジェンスのための単一プラットフォームを提供します。これにより、チームがプロジェクトで協力し、データを共有することが容易になります。
- スケーラビリティ:Azure Databricksは、最も要求の厳しいワークロードのニーズに対応できるよう拡張可能です。ペタバイト規模のデータと数千の同時ユーザーを処理できます。
- パフォーマンス:Azure Databricksはパフォーマンスに最適化されており、データから迅速かつ効率的にインサイトを提供できます。
- 使いやすさ:Azure Databricksは使いやすく、ユーザーがすぐに始められるよう、様々なツールや機能を提供しています。
全体として、Azure Databricksは強力かつ多機能な分析プラットフォームであり、幅広い課題の解決に活用できます。エンドツーエンドの分析およびAIソリューションの構築と展開を目指すあらゆる規模の組織にとって優れた選択肢です。
最適なAzure Databricksアーキテクチャ
最適なAzure Databricksアーキテクチャは、組織の具体的なニーズとサポート予定のユースケースによって異なります。ただし、スケーラブルで効率的かつ安全なアーキテクチャを設計するために従うべき一般的なベストプラクティスがあります。
Azure Databricksの最適なアーキテクチャ設計に関するヒントを以下に示します:
- 階層型アーキテクチャを採用する:階層型アーキテクチャでは、データとワークロードをランディングゾーン、データレイク、データウェアハウスなどの異なる層に分離します。これにより、データとワークロードの管理が容易になるだけでなく、パフォーマンスとセキュリティも向上します。
- Delta Lakeの使用:Delta Lakeはオープンソースのストレージ形式であり、ACIDトランザクションやその他の機能を提供するため、Azure Databricksでのデータ保存に最適です。またSparkと互換性があるため、既存のSparkコードを使用してデータの処理や変換を行うことができます。
- オートスケーリングを使用する:オートスケーリングにより、Azure Databricks は需要に基づいてクラスターを自動的にスケールアップまたはスケールダウンできます。これにより、コンピューティングコストの削減が可能になります。
- マネージドサービスを利用:Azure Databricksは、マネージドノートブックやマネージドストリーミングなど、さまざまなマネージドサービスを提供します。これらのサービスは、Azure Databricks環境の管理に伴う運用上の負担を軽減するのに役立ちます。
- セキュリティ機能の利用:Azure Databricksは、ロールベースのアクセス制御(RBAC)や暗号化など、さまざまなセキュリティ機能を提供します。これらの機能は、データやワークロードを不正アクセスから保護するのに役立ちます。
以下は、階層化された Azure Databricks アーキテクチャの例です:
- ランディングゾーン:ランディングゾーンは、データが最初に Azure Databricks に取り込まれる一時的な保存領域です。ランディングゾーンは Azure Blob Storage または Azure Data Lake Storage Gen2 に保存できます。
- データレイク:データレイクは、形式や構造に関わらず、すべてのデータを一元的に保管するリポジトリです。データレイクは Azure Data Lake Blob Storage または Azure Data Lake Storage Gen2 に保存できます。
- データウェアハウス:データウェアハウスは、分析クエリやレポートの実行向けに高度に最適化されたデータストアです。データウェアハウスはAzure Synapse AnalyticsまたはAzure SQL Databaseに保存できます。データレイクとデータウェアハウスの違いを参照してください。
Azure Databricksクラスターは、ランディングゾーンとデータレイク内のデータにアクセスして、処理および変換タスクを実行できます。処理および変換されたデータは、分析目的でデータウェアハウスにロードできます。
これはAzure Databricksアーキテクチャの一例に過ぎません。選択する具体的なアーキテクチャは、お客様の特定のニーズとユースケースによって異なります。
Azure Databricks アーキテクチャ設計に関する追加のベストプラクティスを以下に示します:
- バージョン管理システムを使用する:Gitなどのバージョン管理システムを使用して、Azure Databricksノートブックやその他のコードの変更を追跡します。これにより、他のユーザーとの共同作業が容易になり、必要に応じて変更をロールバックできるようになります。
- ユニットテストを使用する:Azure Databricks コードのテストにはユニットテストを使用してください。これにより、バグを早期に特定し修正することが可能になります。
- 統合テストを使用する:Azure Databricks コードを、データソースやデータウェアハウスなど、アーキテクチャの他のコンポーネントと組み合わせてテストするために統合テストを使用します。これにより、アーキテクチャ全体が期待通りに連携していることを確認できます。
- アーキテクチャの監視:Azure Databricks アーキテクチャを監視し、パフォーマンスやセキュリティの問題を特定して解決します。Azure Databricks Monitoring を使用してクラスターやジョブを監視できます。
これらのベストプラクティスに従うことで、スケーラブルで効率的、かつ安全で信頼性の高い Azure Databricks アーキテクチャを設計できます。
Databricksの主要なAzure統合
Databricksは、シームレスで強力なデータ分析および機械学習環境を提供するため、Azureとの複数の連携機能を提供しています。これらの連携はAzureサービスの機能を活用し、データエンジニアリング、データサイエンス、機械学習のワークフローを強化します。
DatabricksとAzureの主な統合機能は以下の通りです:
Azure Databricks サービス– Azure Databricks 自体は、Azure と緊密に統合されたマネージドの Apache Spark およびデータ分析プラットフォームです。データエンジニアとデータサイエンティストがビッグデータおよび機械学習プロジェクトで共同作業を行うためのコラボレーション環境を提供します。
Azure Blob Storage– DatabricksはAzure Blob Storageとシームレスに連携し、Azure Data Lake StorageまたはAzure Blob Storageコンテナに保存されたデータへのアクセスと処理を容易にします。この連携により、データを効率的に読み書きでき、データエンジニアリングワークフローが強化されます。
Azure Machine Learning– DatabricksはAzure Machine Learningサービスと連携可能であり、データサイエンティストはDatabricksクラスターを使用して機械学習モデルのトレーニングとデプロイを行い、その後簡単にAzureにデプロイして本番環境で使用できます。
Azure Monitor と Azure Log Analytics– Databricks は Azure Monitor および Azure Log Analytics と連携し、Databricks ワークロード向けの監視、ロギング、診断機能を提供します。この連携により、パフォーマンス調整やトラブルシューティングが容易になります。
Azure Active Directory– Azure Active Directory を使用したシングルサインオンは、Azure Databricks にサインインする最適な方法です。Azure Databricks は Azure AD との連携による自動ユーザープロビジョニングもサポートしており、新規ユーザーの作成、適切なアクセス権限の付与、アクセス権限の解除を伴うユーザーの削除が可能です。
Azure データ レイク ストレージ– Azure Databricks の ADLS ネイティブ コネクタは、データ レイクへの複数のアクセス方法をサポートします。Azure Active Directory 資格情報パススルーを使用し、Azure Databricks へのログインに使用する Azure AD 同一性情報と同じものを活用することで、データ アクセス セキュリティを簡素化できます。データ アクセスは、既に設定済みの ADLS ロールとアクセス制御リスト (ACL) を通じて制御されます。
Azure Data Factory– Azure Data Factoryを使用してAzure Databricksジョブをシームレスに実行し、90以上の組み込みデータソースコネクタを活用して、すべてのデータソースを単一のデータレイクに取り込みます。ADFは、信頼性の高いデータパイプラインの構築を支援するため、組み込みのワークフロー制御、データ変換、パイプラインスケジューリング、データ統合など、多くの機能を提供します。
Azure Synapse Analytics– Azure DatabricksはAzureサービスと連携し、MicrosoftのWebおよびモバイルアプリケーション構築において、分析、ビジネスインテリジェンス(BI)、データサイエンスを統合します。Azure DatabricksとAzure Synapse間の高性能コネクタにより、ストリーミングデータのサポートを含むサービス間の高速データ転送が実現されます。
Power BI– レイクハウス戦略を採用する際に顧客が求める主要機能の一つは、BIツールを用いてデータレイクから直接データを効率的かつ安全に消費する能力です。これにより、従来のようにデータレイクに保存済みのデータをBI利用のためにデータウェアハウスへコピーするフローに伴う追加のレイテンシ、コンピューティング、ストレージコストを削減できます。 Power BIのAzure Databricksコネクタは、データレイクに保存されたデータに対して、より安全でインタラクティブなデータ可視化体験を実現します。
Azure DevOps– Azure DatabricksはAzure DevOpsと連携し、継続的インテグレーションおよび継続的デプロイメント(CI/CD)を実現します。Azure DevOpsをGitプロバイダーとして設定し、統合されたバージョン管理機能を活用してください。
Azure 仮想ネットワーク– Azure Databricks のデフォルトのデプロイは、仮想ネットワーク (VNet) を含む Azure 上の完全管理サービスです。Azure Databricks は、ネットワークセキュリティルールを完全に制御できる、お客様自身の仮想ネットワーク内でのデプロイ(VNet インジェクションとも呼ばれる)もサポートしています。
Azure Event Hubs– Azure Event Hubs を Azure Databricks に接続し、到着したメッセージを処理することで、ライブストリーミングデータからインサイトを取得します。Event Hubs と Azure Databricks を使用すれば、あらゆる IoT デバイスからの毎秒数百万件のイベントや、Web サイトのクリックストリームログをストリーミングし、ほぼリアルタイムで処理できます。
Azure Key Vault– Azure Key Vaultとの統合により、キーやパスワードなどのシークレットを管理します。デフォルトでは、すべてのAzure Databricksノートブックと結果は、異なる暗号化キーで保存時に暗号化されます。ノートブックと結果の暗号化に使用するキーを自身で所有・管理したい場合は、BYOK(Bring Your Own Key)を利用できます。
Azure機密コンピューティング– お客様はAzure機密仮想マシン(VM)上でAzure Databricksワークロードを実行できます。Azure機密コンピューティングのサポートにより、お客様は使用中のデータを暗号化することで機密性とプライバシーを強化した、Databricks Lakehouse上のエンドツーエンドデータプラットフォームを構築できます。これは、保存中のデータを暗号化するための顧客管理キー(CMK)のサポートを基盤としています。
Azure Databricks の価格
Azure Databricksの料金体系は、主に2つの要素に基づいています:
- Databricks Units (DBU):DBUは処理能力の単位です。必要なDBUの数は、ワークロードの規模と複雑さに依存します。
- ストレージ費用:Azure Databricks はデータを Azure Blob Storage または Azure Data Lake Storage Gen2 に保存します。お客様のデータに関連するストレージ費用が課金されます。
Azure Databricksでは、以下の料金プランを含む様々なオプションを提供しています:
- 従量課金制:これは最も柔軟な料金オプションです。ご利用のDBU数と消費ストレージ量に基づいて課金されます。
- コミットメント利用:予測可能なワークロードがある場合、この価格オプションでコスト削減が可能です。1年または3年の期間において、一定数のDBUをコミットします。
- スポットインスタンス:時間的制約のないワークロードには、コスト効率の高い選択肢となる場合があります。スポットインスタンスは割引価格で利用可能ですが、Azureが他のワークロードのためにその容量を必要とする場合、終了される可能性があります。
Azure Databricks のワークロードのコストを見積もるには、Azure Databricks の価格計算ツールをご利用いただけます。
Azure Databricksでコストを節約するためのヒントをいくつかご紹介します:
- オートスケーリングを使用する:オートスケーリングにより、Azure Databricks は需要に基づいてクラスターを自動的にスケールアップまたはスケールダウンできます。これにより、コンピューティングコストの削減が可能になります。
- マネージドサービスを利用:Azure Databricksは、マネージドノートブックやマネージドストリーミングなど、さまざまなマネージドサービスを提供します。これらのサービスは、Azure Databricks環境の管理に伴う運用上の負担を軽減するのに役立ちます。
- スポットインスタンスの利用:時間的制約のないワークロードには、コスト効率の高い選択肢としてスポットインスタンスが利用できます。スポットインスタンスは割引価格で提供されますが、Azureが他のワークロードのためにその容量を必要とする場合、強制終了される可能性があります。
全体として、Azure Databricksはコスト削減に役立つ多様な価格オプションと機能を提供します。
Azure Databricks のサポート
まず第一に、企業はAzure Databricksがデフォルトでは基本的なAzureサポートのみを含むことを理解すべきです。Azure向け統合サポートまたはUS Cloudにおけるサードパーティ製Azureサポートを利用することで、サポートを大幅に強化できます。
Azure Databricksのサポートは、以下のさまざまなチャネルを通じて年中無休でご利用いただけます:
- サポートポータル:Azure Databricks サポートポータルを通じてサポートチケットを作成および追跡できます。
- チャットサポート:Microsoftのサポートエンジニアとリアルタイムでチャットできます。
- 電話サポート:マイクロソフトのサポートに電話し、サポートエンジニアと話すことができます。
- コミュニティサポート:Azure Databricks コミュニティフォーラムで、他の Azure Databricks ユーザーに質問したり、助けを得たりできます。
ご利用いただけるサポートのレベルは、Azure Databricksのサポートプランによって異なります。Azure Databricksでは、以下のサポートプランを含む様々なプランを提供しています:
- 基本サポート:Azure Databricks のすべてのサブスクリプションには基本サポートが含まれます。サポートポータルとコミュニティサポートへのアクセスを提供します。
- 標準サポート:標準サポートは、チャットおよび電話サポートへのアクセスを含む、より高度なサポートを提供します。
- プレミアムサポート:プレミアムサポートは最高レベルのサポートを提供し、専任サポートチームへのアクセスを含みます。
ご自身のニーズと予算に最も合ったサポートプランをお選びいただけます。
Azure Databricksのサポートを受けるには、Azure Databricksサポートポータルからサポートチケットを作成するか、Microsoftサポートエンジニアとリアルタイムでチャットできます。
MicrosoftまたはUS Cloudのいずれかを利用する場合、Azure Databricksサポートを最大限に活用するためのヒントを以下に示します:
- 具体的に:サポートチケットを作成する際は、発生している問題について可能な限り具体的に記載してください。これによりサポートチームが問題をより迅速に解決できます。
- 詳細な情報を提供してください:サポートチームに提供できる情報が多ければ多いほど、対応がスムーズになります。これには、表示されているエラーメッセージ、実行中のコード、使用しているデータなどの情報が含まれます。
- 迅速に対応してください:サポートチームは問題解決のため、追加の質問をさせていただく場合があります。問題が迅速に解決されるよう、質問には必ず速やかにご回答ください。
全体として、Azure Databricksでは多様なサポートオプションが用意されており、必要な時に必要な支援を得られるよう支援します。



