データレイク対データウェアハウス。

データレイクとは何か?
データレイクとは、形式やサイズを問わず、すべてのデータを保存する一元化されたリポジトリです。構造化データ、半構造化データ、非構造化データ(テキスト、画像、音声、動画を含む)を保存できます。
データレイクは、従来のデータベースシステムでは処理できないほど大規模または複雑なデータであるビッグデータの保存によく用いられる。
データレイクは、以下のような様々な目的で使用されます:
- アナリティクス:データレイクは、大規模なデータセットに対して分析を実行し、傾向やパターンを特定するために利用できます。この情報は、意思決定の改善、製品やサービスの最適化、新たなビジネスチャンスの開発に活用できます。
- 機械学習:データレイクは機械学習モデルのトレーニングとデプロイに活用できます。機械学習モデルは予測の生成、異常の特定、タスクの自動化に利用可能です。
- データウェアハウジング:データレイクはデータウェアハウスの構築に活用できます。データウェアハウスは、分析クエリやレポートの実行を目的に設計された高度に最適化されたデータストアです。
- データアーカイブ:データレイクは、長期保存のためのデータアーカイブに利用できます。アーカイブされたデータは、コンプライアンス目的や将来の分析に使用できます。
データレイクには、以下のような多くの利点があります:
- スケーラビリティ:データレイクは、最も要求の厳しいワークロードのニーズを満たすために拡張可能です。ペタバイト規模のデータと数千の同時ユーザーを処理できます。
- パフォーマンス:データレイクはパフォーマンスに最適化されており、データから迅速かつ効率的にインサイトを提供できます。
- 柔軟性:データレイクはあらゆる形式のデータを保存できるため、従来型データベースのスキーマに制限されることはありません。
- 費用対効果:データレイクは、大規模なデータセットを保存・管理する費用対効果の高い方法である。
データレイクは、組織がデータから最大限の価値を引き出すのに役立つ強力なツールです。ただし、データレイクは複雑で管理コストが高い場合がある点に留意する必要があります。データレイクを導入する前に、自社のニーズと要件を慎重に検討することが重要です。
以下に、データレイクが実世界でどのように活用されているかの例をいくつか示します:
- 小売業:小売業者はデータレイクを活用し、顧客の購入データを分析して傾向やパターンを特定します。この情報は、商品構成の改善、マーケティングキャンペーンのターゲット設定、店舗レイアウトの最適化に活用できます。
- 金融:金融機関はデータレイクを活用し、顧客データ、市場データ、リスクデータを分析することで、より優れた投資判断を行い、リスク管理を実施しています。
- 製造:製造業者はデータレイクを活用し、機械からのセンサーデータを分析することで、メンテナンスの必要性を予測し、製品品質を向上させます。
- 医療:医療機関はデータレイクを活用し、患者データ、臨床試験データ、研究データを分析することで、患者ケアの向上や新薬・新治療法の開発に取り組んでいます。
データレイクは、企業がデータから最大限の価値を引き出すために活用できる強力なビッグデータツールである。
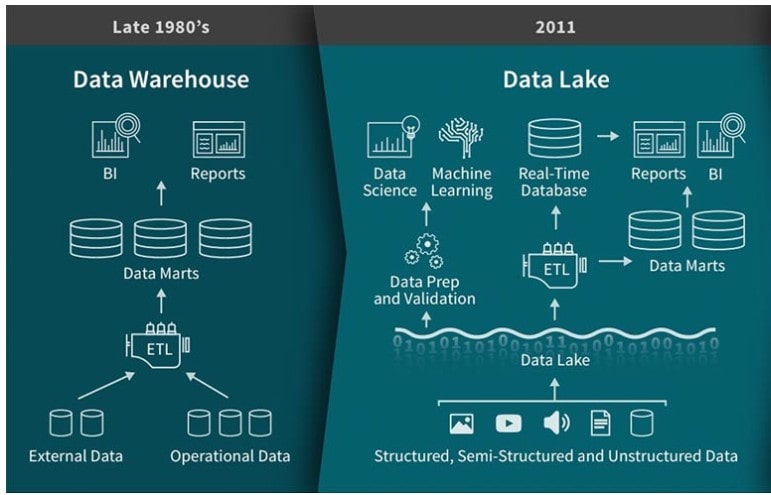
データウェアハウスとは何か?
データウェアハウスは、レポート作成とデータ分析に使用されるシステムである。これは複数のソースから統合され、クエリと分析に最適化された形式に変換されたデータの集中リポジトリである。
データウェアハウスは通常、履歴データを保存するために使用されますが、リアルタイムデータの保存にも使用できます。
データウェアハウスは、以下のような様々な目的で使用されます:
- ビジネスインテリジェンス(BI):データウェアハウスは、ビジネスパフォーマンスに関する洞察を提供するBIレポートやダッシュボードを作成するために使用されます。
- アナリティクス:データウェアハウスは、大規模なデータセットに対して分析を実行し、傾向やパターンを特定するために使用されます。この情報は、意思決定の改善、製品やサービスの最適化、新たなビジネスチャンスの開発に活用できます。
- 機械学習:データウェアハウスは機械学習モデルのトレーニングとデプロイに活用できます。機械学習モデルは予測の生成、異常の特定、タスクの自動化に利用可能です。
データウェアハウスには、次のような多くの利点があります:
- パフォーマンス:データウェアハウスはパフォーマンスを最適化しており、データから迅速かつ効率的に洞察を提供できます。
- スケーラビリティ:データウェアハウスは、最も要求の厳しいワークロードのニーズに対応できるよう拡張可能です。ペタバイト規模のデータと数千の同時ユーザーを処理できます。
- 信頼性:データウェアハウスは信頼性を備え、高可用性を提供するように設計されています。
- セキュリティ:データウェアハウスは、不正アクセスからデータを保護するための様々なセキュリティ機能を提供します。
データウェアハウスは、組織がデータから最大限の価値を引き出すのに役立つ強力なツールです。ただし、データウェアハウスは複雑で、導入や維持に多額の費用がかかる可能性がある点に留意する必要があります。データウェアハウスを導入する前に、自社のニーズと要件を慎重に検討することが重要です。
以下に、データウェアハウスが実世界でどのように活用されているかの例をいくつか示します:
- 小売業:小売業者はデータウェアハウスを活用し、顧客の購入データを分析して傾向やパターンを特定します。この情報は商品構成の改善、マーケティングキャンペーンのターゲット設定、店舗レイアウトの最適化に活用できます。
- 金融:金融機関はデータウェアハウスを活用し、顧客データ、市場データ、リスクデータを分析することで、より優れた投資判断を行い、リスク管理を実施している。
- 製造:製造業者はデータウェアハウスを活用し、機械からのセンサーデータを分析することで、メンテナンスの必要性を予測し、製品品質を向上させている。
- 医療:医療機関はデータウェアハウスを活用し、患者データ、臨床試験データ、研究データを分析することで、患者ケアの向上や新薬・新治療法の開発に取り組んでいます。
全体として、データウェアハウスはあらゆる規模の企業が、増え続けるデータを最大限に活用するために利用できる強力なツールである。
データレイク対データウェアハウス
データレイクとデータウェアハウスはどちらもデータストレージおよび処理ソリューションであるが、それぞれ異なる特徴を持ち、異なる目的のために設計されている。
データレイクとデータウェアハウスの主な違いは以下の通りです:
データ型と構造
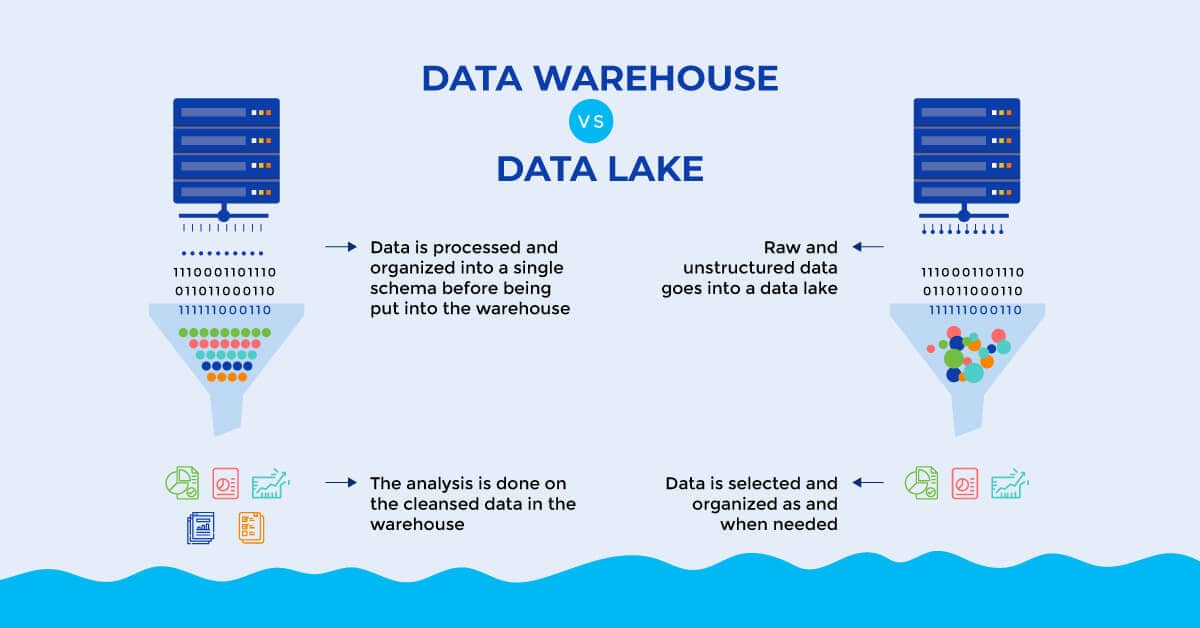
データレイク:データレイクは構造化データ、半構造化データ、非構造化データを格納できます。高い柔軟性を備え、テキスト、画像、動画、ログなど多様な生のデータ形式を、事前定義されたスキーマなしで取り扱うことが可能です。
データウェアハウス:データウェアハウスは主に、明確に定義されたスキーマを持つ構造化データを格納します。データを取り込む前に前処理と構造化が必要となるため、非構造化データや半構造化データを扱う際には柔軟性に欠けます。
スキーマ
データレイク:データレイクは通常、スキーマオンリード方式を採用します。スキーマはデータが読み取られるか処理される際に適用されるため、スキーマの柔軟性が確保され、時間の経過に伴うデータの変化に対応できます。
データウェアハウス:データウェアハウスは書き込み時スキーマ方式を採用しています。データはウェアハウスにロードされる前に、事前定義されたスキーマに変換・構造化される必要があります。スキーマの変更は複雑で時間がかかる場合があります。
データ統合
データレイク:データレイクはデータ統合を目的として設計されており、様々なソースからのデータを大幅な前処理なしに取り込み、統合することが可能です。統合には通常、ETL(抽出、変換、ロード)プロセスが伴います。
データウェアハウス:データウェアハウスも複数のソースからのデータを統合しますが、ロード前にデータを変換およびクリーニングする必要があり、これは通常ETLプロセスの一部として行われます。
データストレージ
データレイク:データレイクは通常、大量の生データを保存する際に費用対効果が高く、テラバイトあたりのコストを抑えつつ膨大なデータを保管するのに適しています。
データウェアハウス:データウェアハウスはクエリ性能を最適化しており、大規模なデータ量に対応するための拡張にはより多くのコストがかかります。高速かつ効率的なクエリを必要とする構造化データの保存に最適です。
データ処理
データレイク:データレイクは汎用性が高く、Azure Data Lake AnalyticsやApache Sparkなどのツールを使用して、バッチ処理、リアルタイム処理、機械学習を含む様々なデータ処理タスクを処理できます。
データウェアハウス:データウェアハウスは主に複雑なSQLベースのクエリとレポート作成を目的として設計されており、ビジネスインテリジェンスや分析ワークロードに適しています。
ユーザーアクセスとツール
データレイク:データレイクは、生データや半構造化データを探索・分析する必要があるデータエンジニア、データサイエンティスト、アナリストによって頻繁に利用されます。データ処理と分析には、PythonやSQLを含む様々なツールや言語が使用されます。
データウェアハウス:データウェアハウスは主にビジネスアナリスト、データアナリスト、意思決定者による構造化データ分析に利用されます。これらは通常、SQLベースのレポート作成ツールやビジネスインテリジェンスプラットフォームに依存しています。
ユースケース
データレイク:データレイクは、データ探索、データサイエンス、ビッグデータ分析、および膨大な量の生データの保存に最適です。様々なソースからデータを迅速に取り込む必要があるシナリオに適しています。
データウェアハウス:データウェアハウスは、ビジネスレポート作成、ダッシュボード、アドホッククエリ向けに高速で信頼性の高い構造化データを提供する点で優れています。これらは構造化データ分析や履歴レポート作成に使用されます。
多くの組織では、データアーキテクチャにおいてデータレイクとデータウェアハウスの両方を活用し、それぞれの強みを生かしている点に留意することが重要です。この組み合わせにより、柔軟性、拡張性、そして幅広いデータ処理・分析要件に対応する能力が実現されます。
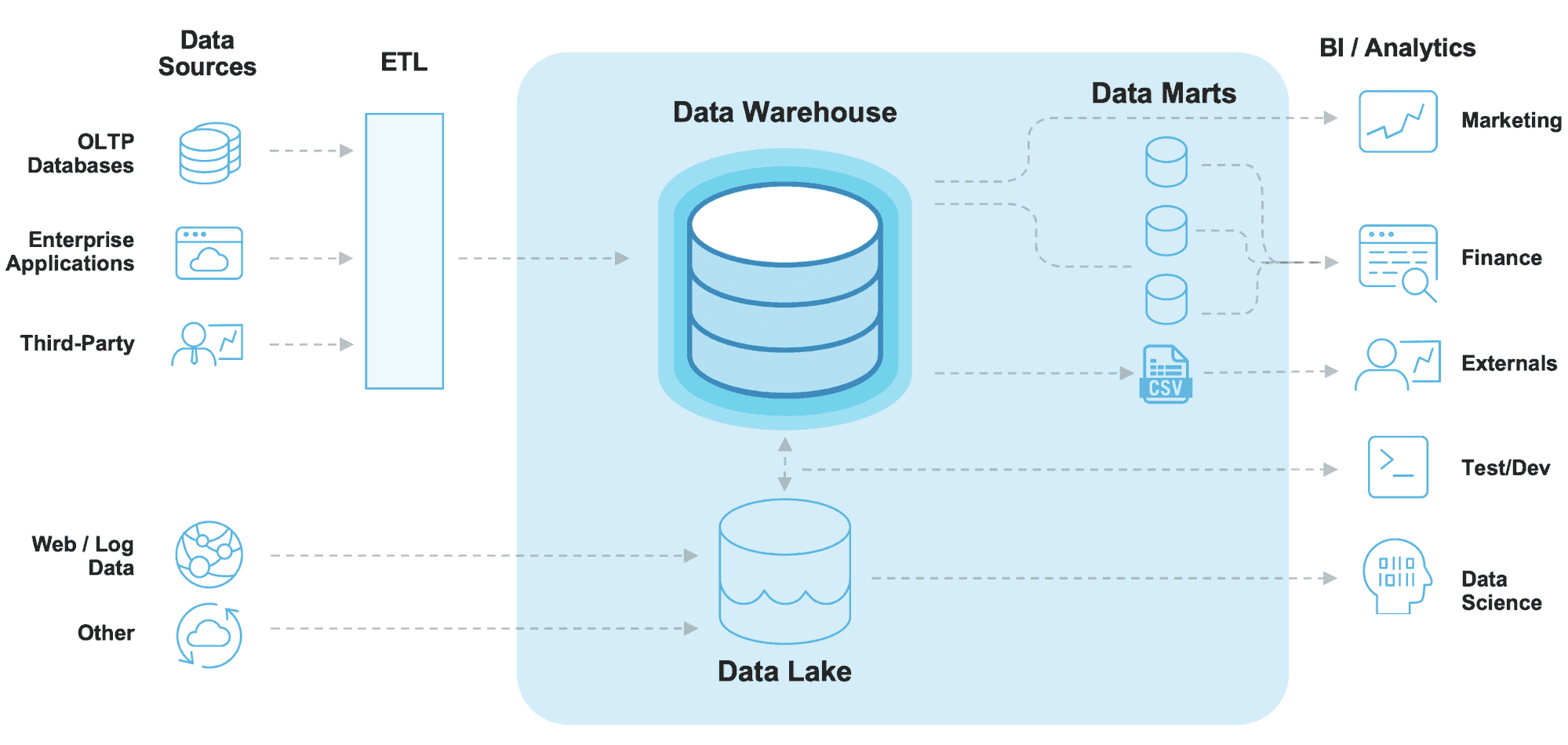

データレイク対データウェアハウスアーキテクチャ
データレイクとデータウェアハウスは、どちらもデータ保存と分析のための重要なツールですが、アーキテクチャとユースケースが異なります。
データレイクアーキテクチャ
- データレイクは、形式や構造を問わず組織の全データを保存するよう設計されています。これにより、ビッグデータや非構造化データの保存に最適です。
- データレイクは通常、スキーマオンリードアーキテクチャを採用しています。これは、データがアプリケーションに読み込まれるまで構造化されないことを意味します。これによりデータレイクは柔軟性と拡張性を得ますが、クエリや分析が困難になる可能性もあります。
- データレイクは、探索的データ分析や機械学習によく利用される。
データウェアハウスアーキテクチャ
- データウェアハウスは、クリーニングおよび処理が施された構造化データを格納するよう設計されています。これにより、レポート作成や分析に最適です。
- データウェアハウスは通常、書き込み時スキーマアーキテクチャを採用しています。これは、データがロードされる際に構造化されることを意味します。 Azureデータウェアハウス。これによりデータウェアハウスはクエリや分析が高速かつ容易になりますが、柔軟性やスケーラビリティが低下する可能性もあります。
- データウェアハウスは、ビジネスインテリジェンスや意思決定支援システムに頻繁に利用される。
どれを選ぶべきか?
組織にとって最適な選択肢は、具体的なニーズと要件によって異なります。大量の非構造化データや半構造化データを保存・分析する必要がある場合は、データレイクが適しています。レポート作成や分析のために構造化データを保存・分析する必要がある場合は、データウェアハウスが適しています。
場合によっては、組織はデータレイクとデータウェアハウスを併用することを選択する場合があります。データレイクは組織の全データを保存するために使用でき、データウェアハウスはレポート作成や分析に必要なデータのサブセットを保存するために使用できます。
データレイクとデータウェアハウスは、いずれもデータ保存と分析のための強力なツールです。企業にとって最適な選択は、具体的なニーズと要件によって異なります。
以下は、データレイクとデータウェアハウスのアーキテクチャにおける主な相違点をまとめた表です:
| 特性 | データレイク | データウェアハウス |
|---|---|---|
| データ構造 | 非構造化、半構造化、構造化 | 構造化された |
| スキーマ | 読み込み時スキーマ | 書き込み時スキーマ |
| パフォーマンス | 遅い | より速く |
| スケーラビリティ | よりスケーラブル | 拡張性が低い |
| 柔軟性 | より柔軟な | 柔軟性が低い |
| ユースケース | 探索的データ分析、機械学習 | レポート作成、分析、ビジネスインテリジェンス |

データレイクおよびデータウェアハウスへの対応
まず第一に、企業はクラウドベースのデータレイクやデータウェアハウスには通常、デフォルトでAzure/AWS/GCの基本サポートしか含まれていないことを理解すべきです。プレミアムOEMサポートやサードパーティサポートを利用することで、サポートを大幅に強化できます。
例えばマイクロソフトを見てみましょう: Azure Data Lake およびデータウェアハウスに関するサポートは、以下の多様なチャネルを通じて年中無休で提供されています:
- サポートポータル:Azure Data Lake/Data Warehouse サポートポータルを通じて、サポートチケットを作成および追跡できます。
- チャットサポート:Microsoftのサポートエンジニアとリアルタイムでチャットできます。
- 電話サポート:マイクロソフトのサポートに電話し、サポートエンジニアと話すことができます。
- コミュニティサポート:Azure Data Lake/Data Warehouse コミュニティフォーラムで、他の Azure Data Lake/Data Warehouse ユーザーに質問したり、助けを得たりできます。
ご利用いただけるサポートのレベルは、Azure Data Lake/Data Warehouseのサポートプランによって異なります。Azure Data Lake/Data Warehouseでは、以下のサポートプランを含む様々なプランを提供しています:
- 基本サポート:Azure Data Lake/Data Warehouse のすべてのサブスクリプションには基本サポートが含まれます。サポートポータルとコミュニティサポートへのアクセスを提供します。
- 標準サポート:標準サポートは、チャットおよび電話サポートへのアクセスを含む、より高度なサポートを提供します。
- プレミアムサポート:プレミアムサポートは最高レベルのサポートを提供し、専任サポートチームへのアクセスを含みます。ユニファイドサポートまたはUSクラウドでさらに拡張できます。
ご自身のニーズと予算に最も合ったサポートプランをお選びいただけます。
Azure Data Lake/Data Warehouse のサポートを受けるには、Azure Databricksサポート ポータルからサポート チケットを作成するか、Microsoft サポート エンジニアとリアルタイムでチャットできます。
Microsoft または US Cloud のいずれかを使用して Azure Data Lake/Data Warehouse のサポートを最大限に活用するためのヒントを以下に示します:
- 具体的に:サポートチケットを作成する際は、発生している問題について可能な限り具体的に記載してください。これによりサポートチームが問題をより迅速に解決できます。
- 詳細な情報を提供してください:サポートチームに提供できる情報が多ければ多いほど、対応がスムーズになります。これには、表示されているエラーメッセージ、実行中のコード、使用しているデータなどの情報が含まれます。
- 迅速に対応してください:サポートチームは問題解決のため、追加の質問をさせていただく場合があります。問題が迅速に解決されるよう、質問には必ず速やかにご回答ください。
全体として、Azure Data Lake/Data Warehouseでは、必要な時に必要な支援を得られるよう、様々なサポートオプションが用意されています。



